
Leer in 5 minuten
- De complexiteit van datamigratie bij de overgang naar een nieuw systeem
- Waarom datavirtualisatie deze complexiteit voor een groot deel wegneemt
- Hoe je daarmee de eerste stap zet op weg naar een flexibelere data-architectuur
Kostbare migratie van data is voor veel bedrijven de grootste horde bij de overgang naar een nieuw ERP-, CRM-, financieel- of bijvoorbeeld ordersysteem. Maar zonder de migratie van alle informatie kan de nieuwe applicatie niet functioneren en werkt je data warehouse met alle bijbehorende rapportages en dashboards niet meer. Toch?
Het antwoord is nee. Een grote misvatting van veel bedrijven is dat ze alle data uit het bestaande systeem moeten migreren naar het nieuwe systeem, terwijl veel historische data helemaal niet meer relevant is voor het operationele proces. Natuurlijk is die informatie wel nodig voor analyse en rapportage, maar waarom lossen we dat op met een complexe migratie tussen systemen en niet op de plek waar de data gebruikt wordt: dichtbij de rapportages, analyses en dashboards?
Tijdrovende oplossing op de verkeerde plek
Laat ik even kort terugpakken op de traditionele manier van datamigratie waar veel bedrijven bijna automatisch voor kiezen. Bij de overgang naar een nieuw systeem worden meestal twee opties overwogen. De eerste optie is het migreren van alle data uit het bestaande systeem naar het nieuwe systeem. Een zeer complexe operatie, omdat data tussen twee zeer ingewikkelde datamodellen – soms wel met duizenden tabellen – vertaald moet worden. Vervolgens moeten er ETL-processen worden ontwikkeld om alle (nieuwe en gemigreerde data) weer netjes in het data warehouse en de data marts te krijgen. Met een beetje pech moet het datamodel van het data warehouse ook worden aangepast en als gevolg daarvan ook de rapportages en dashboards. Een enorme operatie die maanden of zelfs jaren kan duren!
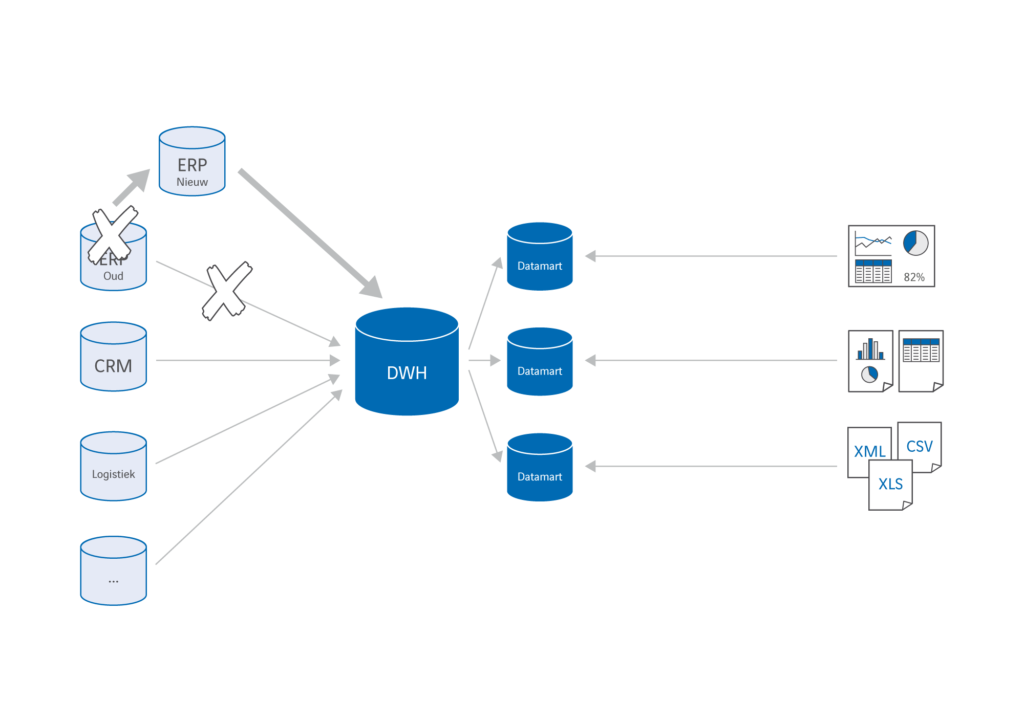
De andere optie is om het oude en nieuwe systeem naast elkaar te laten bestaan. Weliswaar maakt dit de migratie tussen de twee systemen overbodig, maar de complexiteit verschuift hierbij alleen maar. In het data warehouse moet je in dit geval immers twee datastromen samenvoegen in één informatiemodel. Ook dat gaat vaak gepaard met aanpassingen in datamodel, data marts en rapportages. Je hoeft geen IT-expert te zijn om te begrijpen hoe ingewikkeld dit is en soms bijna onmogelijk.
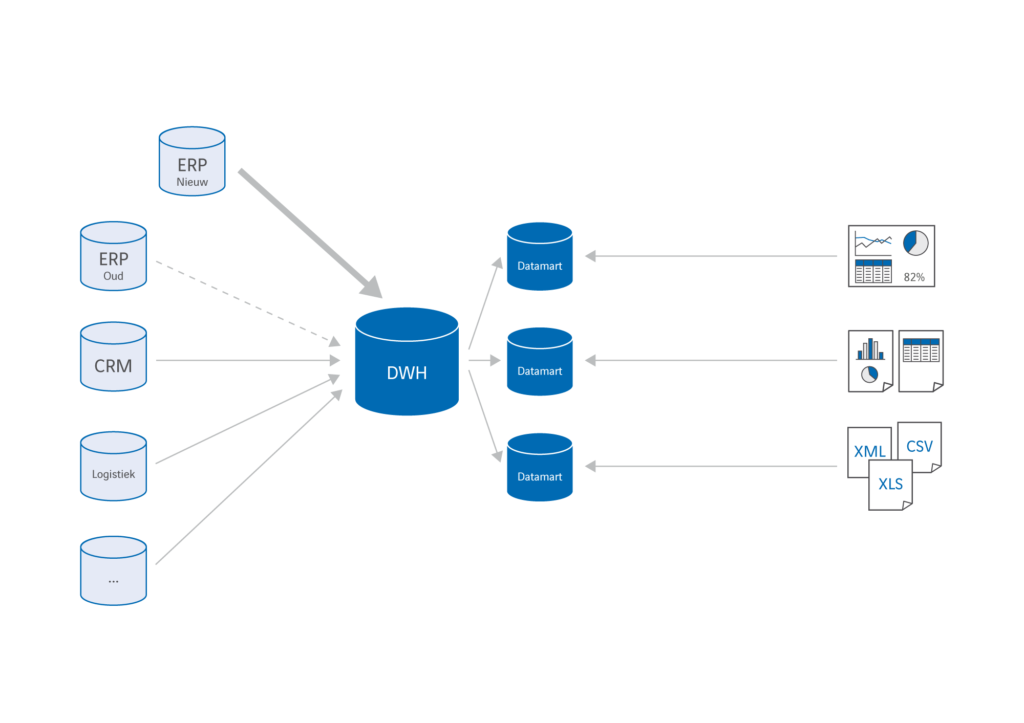 Een bijkomende complicatie is dat belangrijke systemen vaak niet in één keer gemigreerd worden, maar gefaseerd over afdelingen, regio’s, gebruikersgroepen of functionaliteiten. Dat betekent dat data die van belang is voor BI-toepassingen voor langere tijd uit twee systemen gehaald moet worden. Het draait dus niet om een eenmalige omzetting, maar om een geleidelijk proces waarbij de onderliggende gegevensbron van (delen van) rapportages en dashboards geleidelijk verandert.
Een bijkomende complicatie is dat belangrijke systemen vaak niet in één keer gemigreerd worden, maar gefaseerd over afdelingen, regio’s, gebruikersgroepen of functionaliteiten. Dat betekent dat data die van belang is voor BI-toepassingen voor langere tijd uit twee systemen gehaald moet worden. Het draait dus niet om een eenmalige omzetting, maar om een geleidelijk proces waarbij de onderliggende gegevensbron van (delen van) rapportages en dashboards geleidelijk verandert.
Het probleem bij deze twee opties is dat we proberen een probleem aan het einde van het datalandschap – hoe halen we de oude en nieuwe data op voor BI-toepassingen? – op te lossen met een datamigratie aan het begin van dat landschap. Dat is niet alleen omslachtig, bedrijven onderschatten vaak ook de tijd en kosten die ze kwijt zijn om de informatievoorziening weer op orde te krijgen. Tijdens de overgang naar een nieuw systeem ontstaan er allerlei problemen met rapportages, dashboards en analyses die onvolledig of niet betrouwbaar zijn. Soms kost het maanden of zelfs jaren om dit te herstellen.
Snel en soepel
Zou het niet veel makkelijker zijn als je alleen de stamdata die noodzakelijk is voor de werking van het nieuwe systeem (bijvoorbeeld over klanten, producten of prijzen) van je oude naar je nieuwe systeem hoeft te migreren? Dat je geen transactie of procesdata hoeft te vertalen van het ene complexe datamodel naar het andere en dat je geen aanpassingen aan je data warehouse en ETL-processen hoeft te doen? Het klinkt misschien te mooi om waar te zijn, maar het kan écht weet ik uit de praktijk. Door te stoppen met het fysiek dupliceren van data én technologie voor datavirtualisatie in te zetten om data uit verschillende bronnen virtueel te integreren. Met deze aanpak creëer je als het ware een ‘data hub’ die data uit het data warehouse, het oude systeem én het nieuwe systeem als één logisch geheel aanbiedt, zonder die data fysiek te verplaatsen. Waar mogelijk kun je bestaande data marts meteen virtualiseren en zo je architectuur versimpelen. Natuurlijk moeten er nog steeds transformatieregels toegepast worden om data te integreren, maar omdat die integratie virtueel is, gaat dat veel eenvoudiger en sneller. Je hebt nu te maken met één centrale plek waar alle integratie van data via virtuele databasetabellen plaatsvindt en niet met meerdere fysieke datastromen die data in stappen integreren.
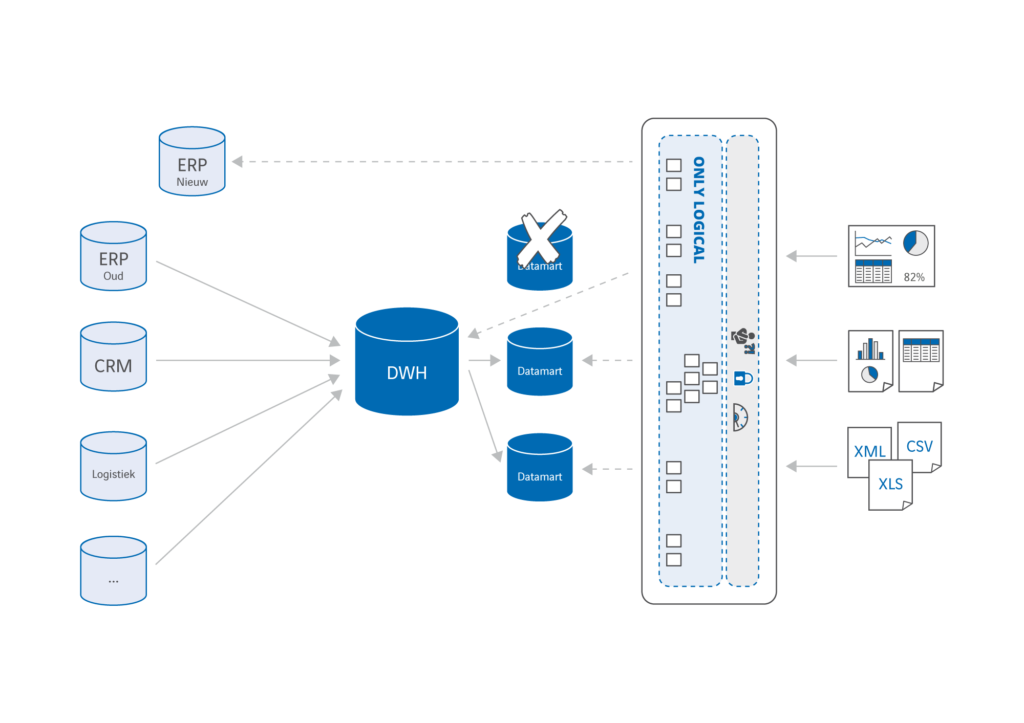 Het mag duidelijk zijn dat deze aanpak bij een geleidelijke migratie van het bestaande naar het nieuwe systeem helemaal grote voordelen biedt. Iedere keer als er een nieuw stuk van het nieuwe systeem in gebruik wordt genomen, moet je immers aanpassingen doorvoeren in je datastromen. Het is nogal een verschil of je dat doet in de virtuele tabellen van een datavirtualisatieplatform, of in meerdere fysieke datamodellen en ETL-processen (mappings). Naast een enorme winst in implementatiesnelheid scheelt dat iedere keer ook enorm veel tijd bij het testen en in productie nemen van wijzigingen.
Het mag duidelijk zijn dat deze aanpak bij een geleidelijke migratie van het bestaande naar het nieuwe systeem helemaal grote voordelen biedt. Iedere keer als er een nieuw stuk van het nieuwe systeem in gebruik wordt genomen, moet je immers aanpassingen doorvoeren in je datastromen. Het is nogal een verschil of je dat doet in de virtuele tabellen van een datavirtualisatieplatform, of in meerdere fysieke datamodellen en ETL-processen (mappings). Naast een enorme winst in implementatiesnelheid scheelt dat iedere keer ook enorm veel tijd bij het testen en in productie nemen van wijzigingen.
Een leuke bijkomstigheid is dat een datavirtualisatieplatform hulpmiddelen biedt om eenvoudig inzicht te geven in de herkomst van gegevens. Zo kunnen gebruikers zien uit welke databronnen de informatie die ze gebruiken afkomstig is en welke transformaties er zijn toegepast.
Oplossing voor de langere termijn
Datavirtualisatie zorgt er niet alleen voor dat de implementatie van een nieuw systeem minder complex en tijdrovend wordt. Met deze aanpak zet je de eerste stap op weg naar een data-architectuur waar gegevens uit operationele systemen niet meer fysiek gecombineerd worden, maar virtueel. Met iedere implementatie van een nieuw systeem of het aansluiten van een nieuwe databron, bouw je verder aan de virtuele data hub en neem je langzaam afscheid van je traditionele data warehouse. Zo ontstaat een veel eenvoudigere architectuur waar bronsystemen in één virtuele laag met elkaar gecombineerd worden. Dat levert flexibiliteit op, stelt je in staat sneller te reageren op wijzigingen, creëert het vermogen om data realtime beschikbaar te stellen en maakt beheer een stuk eenvoudiger. Datavirtualisatie maakt bovendien gebruikt van de rekenkracht van alle systemen in het landschap om de beste performance te garanderen. Kortom, met datavirtualisatie implementeer je je nieuwe systeem veel eenvoudiger, zónder ingewikkelde datamigratie.
Hoeveel tijd zou het jouw organisatie schelen als je kunt stoppen met datamigraties?