
In deel I van dit artikel heb ik uitgelegd hoe je een logisch data warehouse (LDW) kunt implementeren in de cloud op het Microsoft Azure platform. De combinatie van de snelheid en flexibiliteit van het LDW en de schaalbaarheid en stabiliteit van Azure biedt bedrijven geweldige kansen om maximale waarde uit hun data te halen. Microsoft Azure biedt een groot aantal services voor de realisatie van data en analytics oplossingen in de cloud en er komen met grote regelmaat nieuwe functionaliteiten bij. De vorige keer heb ik de belangrijkste services van dit moment geprojecteerd op de referentiearchitectuur van het logisch data warehouse. Om beter te begrijpen hoe die services werken en hoe je ze het beste inzet, zal ik alle componenten in meer detail beschrijven. In dit deel voor de Connect en Combine laag van de LDW-architectuur. In deel III voor de overige architectuurlagen.
Terugblik
Allereerst nog even terug naar de referentiearchitectuur van het LDW en de daarop geprojecteerde componenten van het Azure platform:
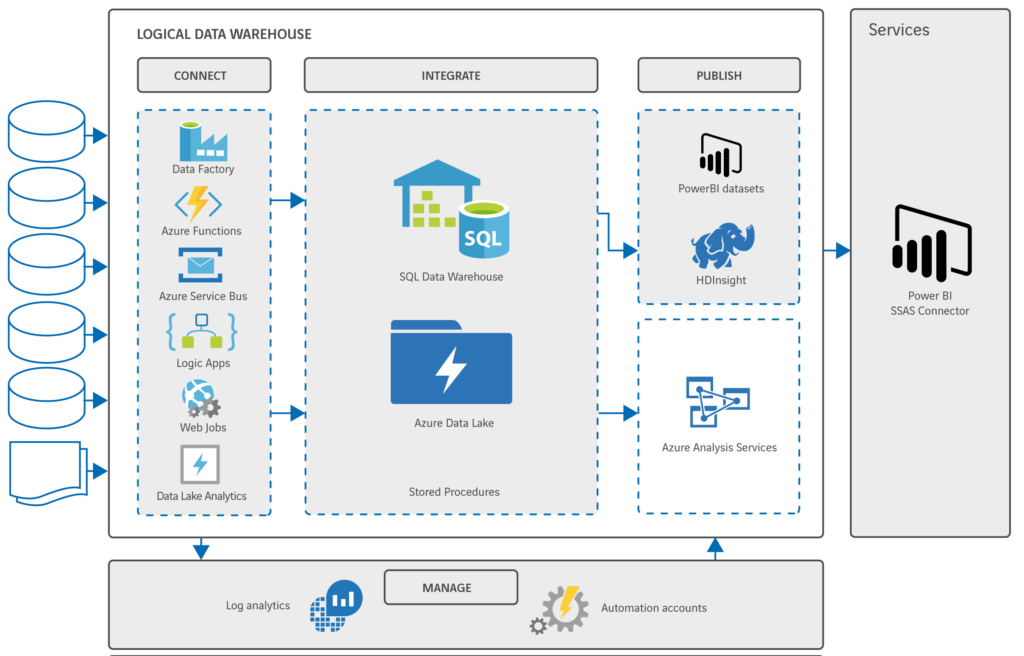
Je ziet al dat sommige componenten op meerdere plekken een rol kunnen spelen. Per ‘laag’ van de architectuur loop ik een voor een de componenten langs.
Connect
In de connect laag komen twee verschijningsvormen voor van het laden van data uit databases, applicaties en interfaces: batch en real time. Voor het in batch verwerken van grote hoeveelheden data uit on-premise systemen naar de Azure cloud is de Data Factory zeer geschikt. Deze service biedt ook andere functionaliteiten, maar de kracht van de Data Factory ligt met name hier. Door de opstarttijd van één minuut is hij minder geschikt voor het triggeren van kleine batch jobs. Dat, en het real time verwerken van data, gaat sneller en eenvoudiger met andere tools binnen Azure. Door gebruik te maken van een Logic App op basis van een API, een WebJob of een Azure Function in C# of Javascript. Of door een Azure Service Bus op te zetten. Laten we eens in meer detail naar deze mogelijkheden kijken…
Azure Data Factory biedt de snelste methode om on-premise data naar de Azure cloud te transporteren. Door de integratiemogelijkheden met een verscheidenheid aan bronsystemen is dit dé service om grote brokken data naar de cloud te brengen. Omdat de Data Factory gebaseerd is op json kun je scripts maken om complete workflows te genereren. De wizard maakt het eenvoudig om nieuwe connecties te leggen en een workflow op te zetten. Zelfs grote, complexe workflows zijn eenvoudig te maken en beheren.
| VOORDELEN |
| De snelste service voor het verwerken van lokale data |
| Veel standaardmogelijkheden voor connecties naar allerlei systemen |
| Uitgebreide scripting mogelijkheden |
| NADELEN |
| Lange opstarttijd |
| Er kunnen geen parameters worden meegeven aan een job |
Azure Logic Apps zijn ideaal om kleine datasets naar en binnen Azure te transporteren. Met de overzichtelijke userinterface en de aanwezige standaard connectoren kun je heel eenvoudig een nieuwe workflow opzetten. De enorme set aan mogelijke triggers kun je gebruiken om op allerlei manieren – live of op commando – datasets te synchroniseren met de cloud. Of data nu uit een sharepoint lijst komt of via sftp moeten worden opgehaald, door de standaardconnectoren is bijna alles mogelijk. Bovendien kun je custom connectoren inlezen of zelf nieuwe connectoren definiëren op basis van WSDL.
| VOORDELEN |
| Overzichtelijke en eenvoudige interface |
| Zeer snel op te zetten |
| Uitgebreide set aan standaardconnectoren |
| NADELEN |
| Niet goed in het (sequentieel) verwerken van grotere datasets |
| Limiet op de omvang van een dataset (29,9 MB voor een csv op het moment van schrijven) |
| Time-outs op SQL-connectoren (90 sec. op het moment van schrijven) |
| Kan duur uitvallen omdat je afrekent per uitgevoerde actie |
Azure Service Bus helpt je een enterprise service bus op te zetten om berichten ‘loosly coupled’ te delen tussen aanbieders en afnemers van gegevens. De Service Bus integreert standaard met Logic Apps en Azure Functions zodat je real time koppelingen kunt realiseren met bronsystemen zonder afhankelijk te zijn van locatie of technologie van die bron.
| VOORDELEN |
| Eenvoudig op te zetten |
| Real time ontkoppeling van bronsystemen |
| NADELEN |
| Externe applicatie nodig voor beheer |
Azure Functions is een serverloze werkomgeving om C#-code of Javascript on demand uit te voeren zonder specifieke resources toe te wijzen. Hierdoor kun je apps en data-integratie oplossingen ontwikkelen zonder dat je je zorgen hoeft te maken over de onderliggende infrastructuur. Door de standaard connecties met andere Azure componenten kun je allerlei (complexe) data-integratie vraagstukken oplossen. Via de userinterface in de Azure Portal kun je eenvoudig je code aanpassen en je connecties beheren.
| VOORDELEN |
| Support voor meerdere programmeertalen |
| Fully managed omgeving |
| Grote set standaard connecties |
| NADELEN |
| Geen support voor NuGet packages |
Azure WebJobs is een service voor het uitvoeren van volledige web-, mobile- of API-applicaties die in hun eigen omgeving binnen Azure draaien. Deze applicaties staan altijd aan of zijn inschakelbaar via een webhook. Ze worden gemaakt en beheerd in visual studio kunnen van daaruit direct naar Azure worden geupload en in gebruik worden genomen.
| VOORDELEN |
| Volledige applicaties in Azure |
| (Handmatig) schaalbaar |
| NADELEN |
| Niet te beheren vanuit de Azure Portal |
| Programmacode niet zichtbaar vanuit de Azure Portal |
Een speciale rol in de connect laag is weggelegd voor:
Azure Data Lake Analytics
Veel data ‘landt’ in een Azure Datalake, waarmee dit het centrale punt wordt voor alle data in de cloud omgeving. In een aantal gevallen moet data bewerkt en opgeschoond worden voordat die in het data lake landt. Hiervoor kun je U-SQL jobs opzetten in Data Lake Analytics die je vervolgens kunt aanroepen als een stap van een workflow binnen de Data Factory. Zo komt data in de juiste vorm en formaat binnen in de cloud.
| VOORDELEN |
| Krachtige dataverwerking direct in het data lake |
| NADELEN |
| U-SQL taal is nog beperkt in functionaliteit |
Integrate
In de integrate laag spelen met name twee Azure componenten een rol: het Data Lake en het SQL Data Warehouse. Waar het Data Lake de centrale hub is in de cloud, waar alles ‘landt’, is het Azure SQL Data Warehouse de ‘processing engine’ van het Logisch Data Warehouse.
Azure Data Lake Store vormt het centrale punt voor alle databehoefte in de cloud. Door de uitgebreide connectiemogelijkheden van de Data Lake Store is het mogelijk om data naar en uit het data lake te halen vanuit alle andere cloud services. Door de HDFS-structuur kan Azure Data Lake ook uitstekend als basis dienen voor een Hadoop- of Spark-cluster voor gebruik door data scientists. Zo maken zowel het SQL Data Warehouse als de data scientists gebruik van dezelfde basisdata. Door de integratie van Azure Data Lake met Active Directory kan je heel precies controle houden over data door in te stellen wie toegang mag hebben tot welke data. Zorgen over de omvang van je data lake behoren ook tot het verleden, omdat je makkelijk én goedkoop kunt opschalen.
| VOORDELEN |
| Integratie met alle andere services |
| Uitgebreide autorisatiemogelijkheden |
| Goedkoop |
| NADELEN |
| Niet eenvoudig om toegangsrechten (per file) achteraf aan te passen (dus vooraf goed over nadenken) |
SQL Data Warehouse is dé data warehouse oplossing binnen het Azure platform. Deze snelle parallelle (MPP) database is ideaal voor de uitvoering van complexe SQL-code waar rekenkracht voor nodig is. Doordat data wordt opgeslagen in de columnar store is de database echt razendsnel. SQL Data Warehouse is zowel qua opslag als rekenkracht schaalbaar waardoor je altijd precies kunt gebruiken wat je op dat moment nodig hebt. Je kunt de service zelfs helemaal uitzetten als je hem niet nodig hebt. Het op- en afschalen gebeurt niet automatisch, dat doe je handmatig. Daarmee heb je wel exact zelf in de hand wat je gebruikt en waar je voor betaalt.
Met PolyBase – een technologie waarmee data buiten de SQL-database benaderd kan worden op basis van T-SQL zonder dat deze verplaatst hoeft te worden – kunnen gegevens uit andere Azure componenten real time geïntegreerd worden zonder die te dupliceren. Geheel in lijn met de uitgangspunten van het logisch data warehouse! Bovendien kan op deze manier slim gebruik worden gemaakt van bijvoorbeeld de opslagcapaciteit en rekenkracht van het Azure Data Lake vanuit het SQL Data Warehouse, zonder dat de gebruiker de achterliggende technologie hoeft te kennen.
| VOORDELEN |
| Zeer snelle MPP-database |
| Schaalbaar |
| Je betaalt alleen wat je gebruikt |
| (Real time) integratie van data zonder duplicatie |
| NADELEN |
| Niet alle SQL-functies zijn (nog) beschikbaar voor de parallelle versie |
Van data naar informatie
Met deze twee architectuurlagen hebben we een aantal belangrijke principes van het logisch data warehouse geïmplementeerd op Microsoft Azure. In de Integrate laag wordt data uit verschillende bronnen met elkaar geïntegreerd in een logische structuur. Business rules die bedrijfsbreed gelden, worden hier toegepast. Daarnaast minimaliseren we de fysieke duplicatie van gegevens door slim gebruik te maken van (real time) connecties en de Polybase functionaliteit. De volgende stap is uiteraard het beschikbaar stellen van informatie aan afnemers zoals interne en externe gebruikers, applicaties en API’s. In deel III van deze artikelreeks ga ik in detail in op de publish en services laag van de LDW-architectuur. En niet te vergeten: de manier waarop je in Microsoft Azure datastromen en informatiegebruik beheert.
Wat zou het jou opleveren als je een snelle, schaalbare en flexibele data-architectuur kunt realiseren in de cloud?