
Leer in 10 minuten
- Wat de 5 unieke eigenschappen van datavirtualisatie zijn
- Hoe ieder product datavirtualisatie anders invult
- Waar alternatieve oplossingen voor datavirtualisatie achterblijven
Datavirtualisatie is de kinderschoenen ontgroeid. Er komen steeds meer aanbieders die ‘iets doen’ op dit gebied. Maar tussen dat iets doen en echte datavirtualisatie zit flink wat verschil. Wat moet een datavirtualisatie product kunnen? In deze blog zetten we 5 onmisbare eigenschappen van datavirtualisatie op een rij en leggen we enkele alternatieve oplossingen langs de meetlat.
Eigenschappen datavirtualisatie
In de afgelopen tijd probeerden diverse softwareleveranciers een plekje op de markt van datavirtualisatie te veroveren. Denk aan Microsoft, dat recent Polybase introduceerde als onderdeel van SQL Server 2019. Ook IBM heeft een datavirtualisatie-stack, net als langer opererende aanbieders zoals Data Virtuality, Tibco en Denodo. Daarnaast zijn er platformen als Mulesoft en SAP HANA. En we zullen er vast nog een paar vergeten zijn in dit lijstje. Eén ding hebben al deze aanbieders gemeen: ze geven allemaal op hun eigen manier invulling aan datavirtualisatie. Maar de vraag is of al die verschillende oplossingen wel doen wat ze moeten doen. Met andere woorden: wanneer mag je spreken van een écht datavirtualisatieproduct? Je herkent het aan deze 5 eigenschappen:
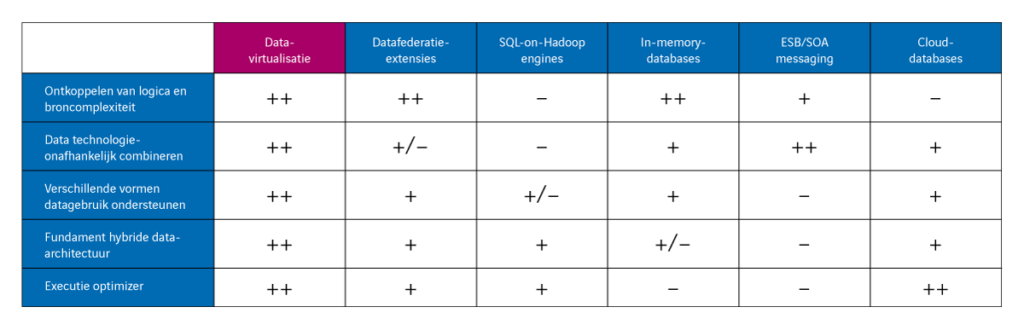
- Ontkoppelen logica en broncomplexiteit
Een datavirtualisatieproduct sluit meerdere bronnen aan. Al deze bronnen bevatten complexiteit. Die complexiteit wil je wegnemen van de eindgebruikers van je data, zodat er geen drempels ontstaan in de informatievoorziening. Daarnaast wil je de logica ook niet door eindgebruikers laten toepassen. Beter is het de logica op één punt binnen je dataplatform los te laten op je data, waarna al je gebruikers ermee aan de slag kunnen. Bij datavirtualisatie moet je dus zowel aan de bronkant als richting de eindgebruiker kunnen ontkoppelen. Zo isoleer je de broncomplexiteit én de logica. - Technologie-onafhankelijk samenwerken en integreren met alle dataopslagtechnieken
Een belangrijke vereiste is natuurlijk ook dat een datavirtualisatieproduct met een veelvoud van technieken integreert en communiceert. Dit met het oog op de broncomplexiteit. Relationele bronnen, dataservices, cloudbronnen, files: je moet al je verschillende soorten bronnen kunnen ontsluiten, op welke technologie ze ook zijn gebaseerd. Hetzelfde geldt voor je dataopslag - Goede backbone voor hybride data-architectuur
Een beetje data-architectuur is tegenwoordig hybride. Een datavirtualisatieproduct integreert allerlei databases samen binnen één architectuur, of ze nu on-premise of in de cloud staan. De verschillende technologieën vullen elkaar daarbij aan. Wil je meer weten over moderne data-architecturen? Lees dan dit artikel. - Verschillende vormen van datagebruik ondersteunen
Wat heb je aan data als je die niet kunt gebruiken? Daarom kijk je bij datavirtualisatie ook altijd naar het doel van je data. Neem governed BI. Daarbij moet altijd de herkomst van de getoonde data inzichtelijk zijn, dus de lineage van de herkomst tot aan bron. Inclusief álle tussenliggende transformaties. Of wat te denken van informatie die op een specifiek moment nodig is: even snel data klaarzetten, ready for use? Of misschien wil je wel data scientists ondersteunen en ze door allerlei data heen laten struinen om zo nieuwe patronen te ontdekken en tot nieuwe inzichten te komen. Datavirtualisatie moet al deze vormen van gebruik ondersteunen. - Goede cost based optimizer
Bij datavirtualisatie is performance ontzettend belangrijk. Maar hoe zorg je voor optimale prestaties bij de uitvoering van een query? Dat doe je met cost based optimization. Een cost based optimizer gaat na welke scenario’s een query kan volgen en bepaalt welk scenario het beste is. Dit hangt af van je datagebruik. Bij datavirtualisatie zijn er dus meerdere wegen naar een snelle selectie en een goede performance: per use-case activeert de optimizer de juiste route naar de benodigde data.

Alternatieve oplossingen voor datavirtualisatie
Nu we de ‘must haves’ van datavirtualisatieproducten kennen, is het goed om ook even te kijken naar alternatieve oplossingen voor datavirtualisatie. Een aantal voorbeelden daarvan zijn datafederatie-extensies van databases, SQL-on-Hadoop engines, in-memory databases, ESB-, SOA- en messaging-producten of cloud-databases. Laten we deze opties kort doorlopen, met de 5 kerneigenschappen van datavirtualisatie in gedachten.
- Geen lineage met datafederatie
Datafederatie lijkt in veel opzichten op datavirtualisatie, maar er zijn essentiële verschillen. Zo kan datafederatie zeker de broncomplexiteit ontkoppelen, maar is de flexibiliteit bij het ontsluiten van bronnen via datafederatie-extensies minder sterk. Kijken we naar het gebruik van data, met de focus op ‘governed BI’, dan ontbreekt het aan functionaliteit om de herkomst van data in beeld te brengen. Ter vergelijking: de huidige datavirtualisatieproducten hebben een catalogus met de lineage tot op het niveau van de metadata. Datafederatie is wél goed in query-optimalisatie, maar zoals gezegd is het aantal verschillende bronnen dat je kunt aansluiten beperkter.
- Datareplicatie nodig bij SQL-on-Hadoop
Bij SQL-on-Hadoop is het ontkoppelen van logica van de bron niet zo eenvoudig, want de data moeten daarvoor in het Hadoop-filesystem staan en vaak is dat niet meteen het geval. Een datareplicatieslag is dan onontkoombaar. Bovendien schiet deze oplossing tekort bij het ontsluiten van verschillende bronnen en het combineren en integreren van structuren. Je verzandt al snel in een onoverzichtelijke reeks datakopieën. En net als bij data-federatie biedt SQL-on-Hadoop je niet per definitie de mogelijkheid om een catalogus met metadata te doorzoeken. De cost based optimizer functioneert prima, maar daar heb je uiteraard alleen iets aan als al je data in Hadoop staan.
- In-memory databases: niet technologie-onafhankelijk
In-memory databases ontkoppelen de logica van de broncomplexiteit voor de gebruiker, net als datavirtualisatieproducten. Ze halen data in hun geheel op uit de bronsystemen, slaan de gegevens op en combineren ze vervolgens met de overige data die nodig zijn voor een query. Deze oplossing werkt echter vaak samen met een specifieke databaseserver en is dus niet technologie-onafhankelijk. Daarbij bieden in-memory databases je weinig tot geen ondersteuning voor datamanagement. Omdat de data eerst uit externe bronnen worden opgehaald en ingeladen in het geheugen, kun je niet gebruikmaken van de mogelijkheden van de databaseserver waar de data al op staan. Daardoor is het executiepad niet altijd het meest optimaal. Logisch dus dat in-memory databases ook niet hoog scoren in cost-based optimization.
- ESB, SOA en messaging: niet geschikt als backbone!
En hoe zit het dan met ESB-, SOA- of messagingproducten? Deze oplossingen gebruik je vooral om data van de ene naar de andere applicatie te transporteren. Ze zijn wel degelijk in staat om logica en broncomplexiteit te ontkoppelen en ze werken technologie-onafhankelijk. Alleen zijn deze oplossingen hoofdzakelijk geschikt voor point-to-point-oplossingen en niet voor verschillende vormen van datagebruik. Daarmee zijn ze dus ook ongeschikt als backbone voor je hybride data-architectuur. Er is ook geen sprake van cost-based optimization, berichten gaan gewoon van a naar b.
- Cloud-databases: eerst alle data over
Cloud-databases bieden je de herkenbaarheid en integratievoordelen van de klassieke on-premise SQL-database. Belangrijkste verschil is dat je de databases niet lokaal in je organisatie host, maar als PaaS-dienst afneemt. Het databasebeheer, zoals patches, performance en beveiliging, maakt deel uit van de dienstverlening. Je bent er dus minder tijd aan kwijt en hoeft minder kennis in huis te hebben.
Waar cloud-databases echt in uitblinken is de ongekende flexibiliteit in het toevoegen van opslagcapaciteit en rekenkracht. Die zijn vaak dynamisch en automatisch aan te passen aan de (tijdelijke) behoefte van je gebruikers. Nadeel is wel dat je alle data naar de cloud-database moet ‘brengen’ om deze voordelen te benutten. Je moet extract- en load processen aanmaken voor iedere bron van waaruit je data laadt. Wil je logica vastleggen in transformatieviews? Dat gaat prima en snel, maar wat vaak ontbreekt is een goede ontwikkelstudio voor overzicht op de ontwikkelde logica in meerdere en soms gestapelde views. Het maakt je beheer ingewikkeld en zorgt voor onoverzichtelijkheid.
Bestaansrecht datavirtualisatie buiten kijf
Onze conclusie? Er zijn verschillende producten op de markt die een of meer eigenschappen van datavirtualisatie ondersteunen. Iedere oplossing heeft zo zijn eigen voor- en nadelen, maar datavirtualisatie heeft duidelijk zijn eigen bestaansrecht en unieke eigenschappen. Om het je makkelijk te maken, hebben we alle oplossingen uit deze blog nog eens naast elkaar gezet in een overzichtelijke tabel.
Hoe profiteert jouw organisatie van échte datavirtualisatie?