
In datagedreven organisaties wordt iedere beslissing onderbouwd met feiten die op data en algoritmes zijn gebaseerd. Data wordt verzameld, gebundeld en geanalyseerd om trends, regels en patronen te identificeren die je helpen bedrijfsprocessen te begrijpen, ondersteunen, verbeteren en versnellen. Hoe mooi zou het dan ook zijn als je met slechts één druk op de knop meteen inzicht krijgt in de huidige status van jouw bedrijfsprocessen maar óók in de kansen om deze processen te optimaliseren? Dit kan met behulp van een Digital Twin: een digitale replica van een proces waarmee in één oogopslag inzicht verkregen kan worden in de huidige status van het proces en waar er nog ruimte is voor verbetering. Maar hoe bouw je een Digital Twin en wat heb je hiervoor nodig?
Collega’s Stijn Henken en Bodien Ypma – beide Business Intelligence Consultant bij Axians – leggen je uit wat een Digital Twin is en gaan in op de mogelijkheden en krachten van een Digital Twin. Zij hebben zelf – tijdens hun afstudeerstage – een Digital twin in IBM Cloud Pak for Data gebouwd. Binnen deze stage hebben zij verschillende competenties, waaronder Data Engineering, Data Visualisatie en Data Science gecombineerd. Voordat Stijn en Bodien ingegaan op hun Digital Twin en de kracht van IBM Cloud Pak for Data, leggen zij eerst uit wat de gebruikte definitie van een Digital Twin is.
Wat is een Digital Twin?
Een Digital Twin is een virtuele representatie van een bedrijfs- of productieproces dat gebruikt kan worden om het proces te simuleren, visualiseren, voorspellen en optimaliseren. Het grote voordeel hiervan is dat optimalisatiemogelijkheden of wijzigingen eerst digitaal uitgeprobeerd kunnen worden voordat deze daadwerkelijk in het proces toegepast worden. Dit voorkomt verspilling en onnodige investeringen. De inzet van een Digital Twin is hiermee heel breed: van het bepalen van de ideale orderpick-route in een magazijn en het voorspellen van levertijden, tot het matchen van voorraad en het opstellen van verkoopprognoses. De potentie is dus enorm.
Het orderverzamelproces als uitgangspunt
Binnen onze afstudeeropdracht is gekozen voor het orderpick proces van een magazijn. Dit omdat het een veel voorkomend probleem is en makkelijk te begrijpen is. In een magazijn kan een Digital Twin gebruikt worden om verschillende optimalisaties aan het licht te brengen. Denk hierbij onder andere aan:
- Het optimaliseren van de looproute voor de orderverzamelaar; een geoptimaliseerde route zorgt voor een kortere looptijd per order.
- Het bepalen van de optimale locatie voor alle producten; een geoptimaliseerde productlocatie zorgt voor besparing in magazijnruimte en een kortere gemiddelde loopafstand per order.
- Het bepalen van een looproute waarbij zo min mogelijk pallets worden gebruikt; het verminderen van palletgebruik zorgt voor een besparing in pallets en een optimaal vervoer van producten.
- Het combineren van orders; het combineren van orders zorgt voor een kortere looptijd per order, omdat producten uit hetzelfde magazijnsegment tegelijk verzameld kunnen worden.
- De meest optimale indeling voor het magazijn; een optimale magazijnindeling bespaart magazijnruimte en indirect op looptijd per order.
In onze Digital Twin is de eerstgenoemde optimalisatie uiteengezet: het bepalen van de kortste route voor het verzamelen van verschillende producten voor een order.
Wat is er nodig voor een Digital Twin?
Data staat centraal binnen een Digital Twin. Voor het verbinden met de databron en het structureren, opslaan en analyseren van de data is IBM Cloud Pak for Data gebruikt. Binnen IBM wordt hierbij gebruik gemaakt van de AI Ladder:
1. Collect
Het verzamelen van data: de data uit het bronsysteem van het magazijn wordt hier samengevoegd en schoongemaakt. Daarnaast worden hier overige bronnen zoals de plattegrond en productlocaties omgezet naar bruikbare data.
2. Organise
Het structureren en opslaan van de verzamelde data: binnen deze stap is de verzamelde data in een Watson Studio omgeving samengebracht en opgeslagen in een IBM Db2 Warehouse. Bij het ontwerpen van dit Data Warehouse is gebruik gemaakt van een Star-schema uit de Kimball methodiek. De data uit dit Data Warehouse is daarna gebruikt voor het berekenen van de beste looproute voor een orderverzamelaar. Hiervoor is in een notebooks binnen Watson Studio het Guided Local Search-algoritme gebruikt.
3. Analyse
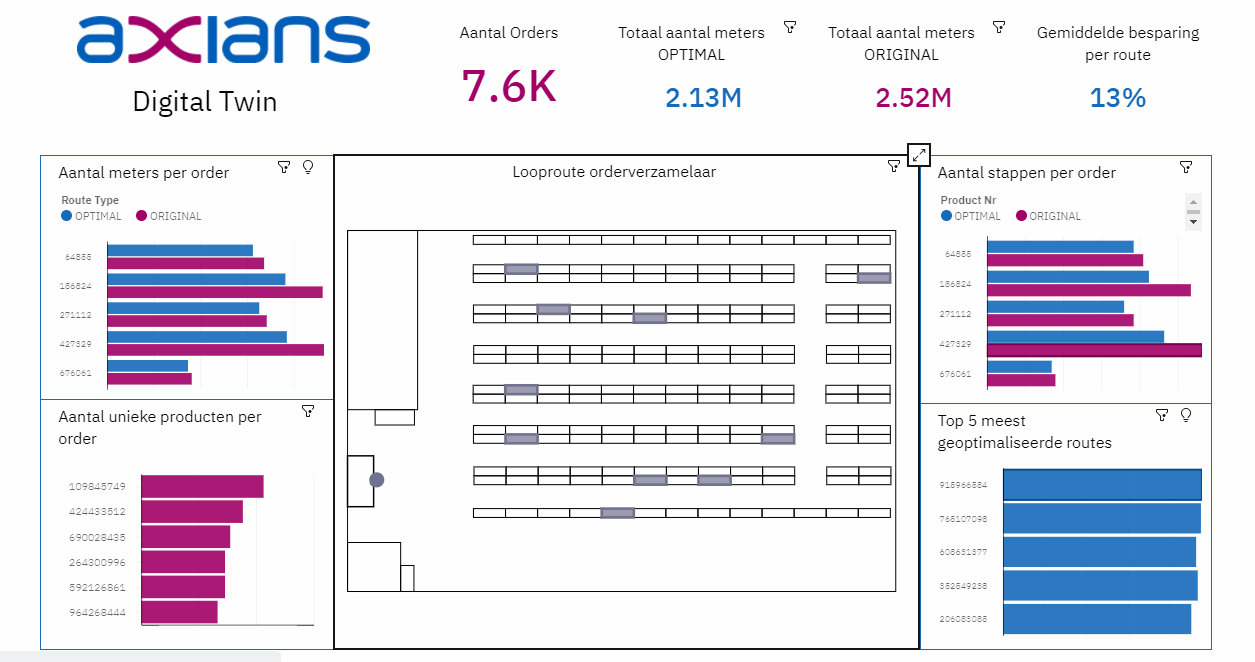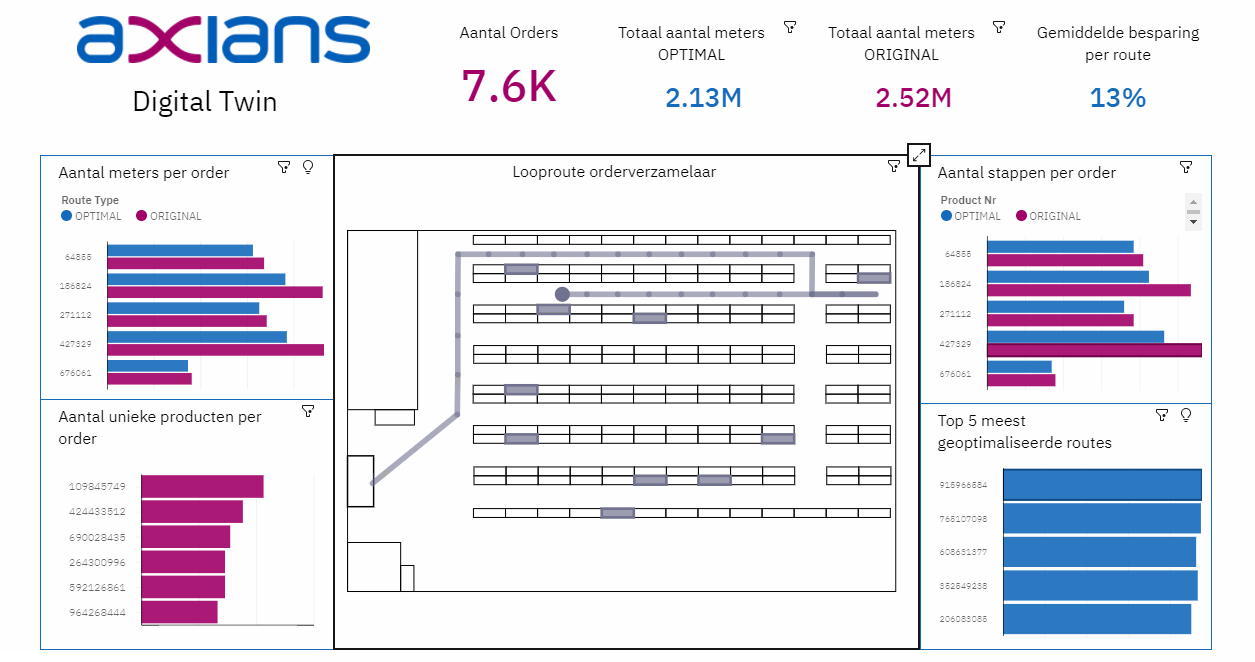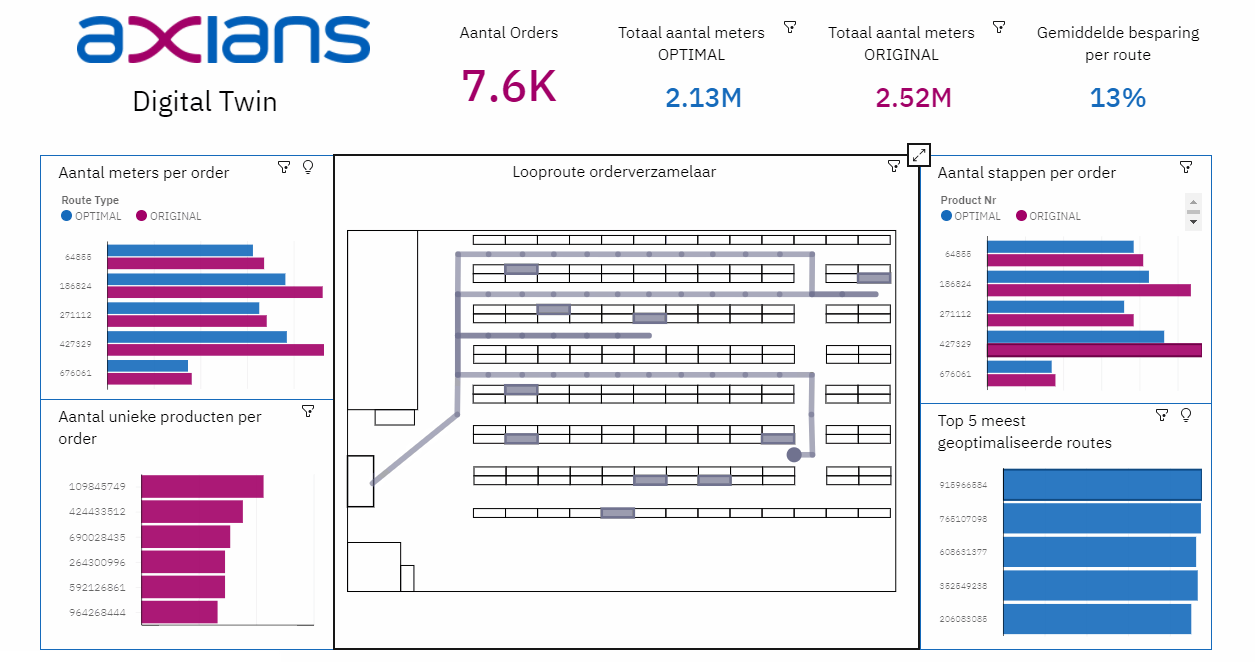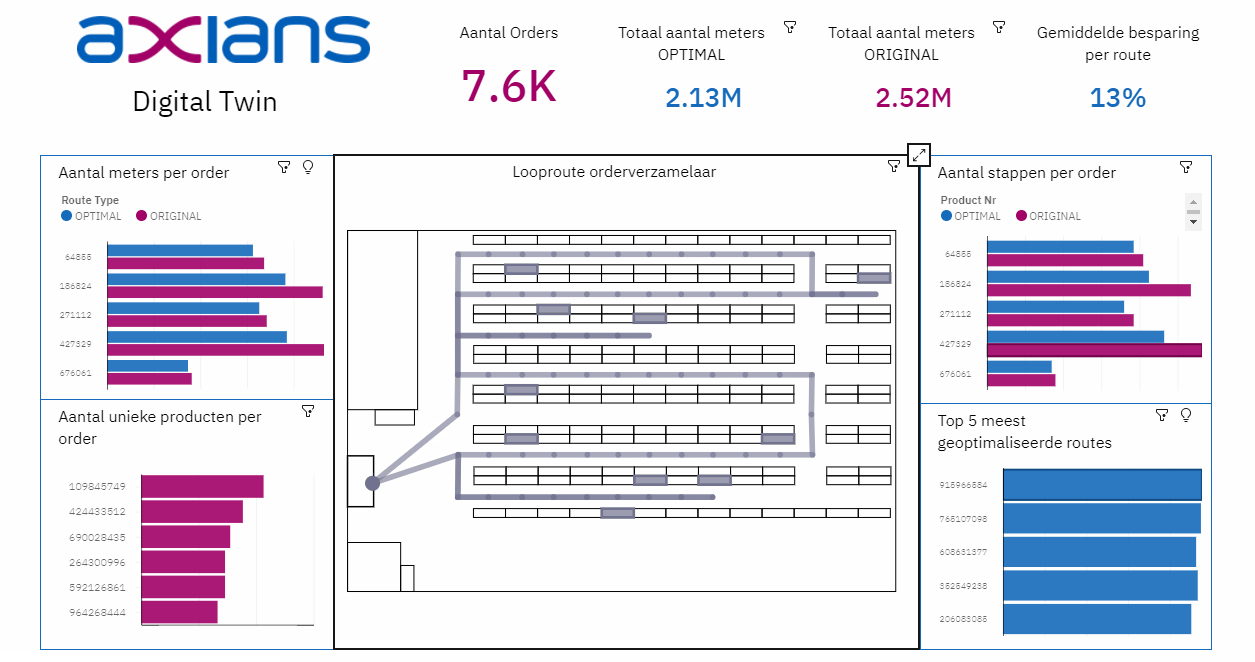
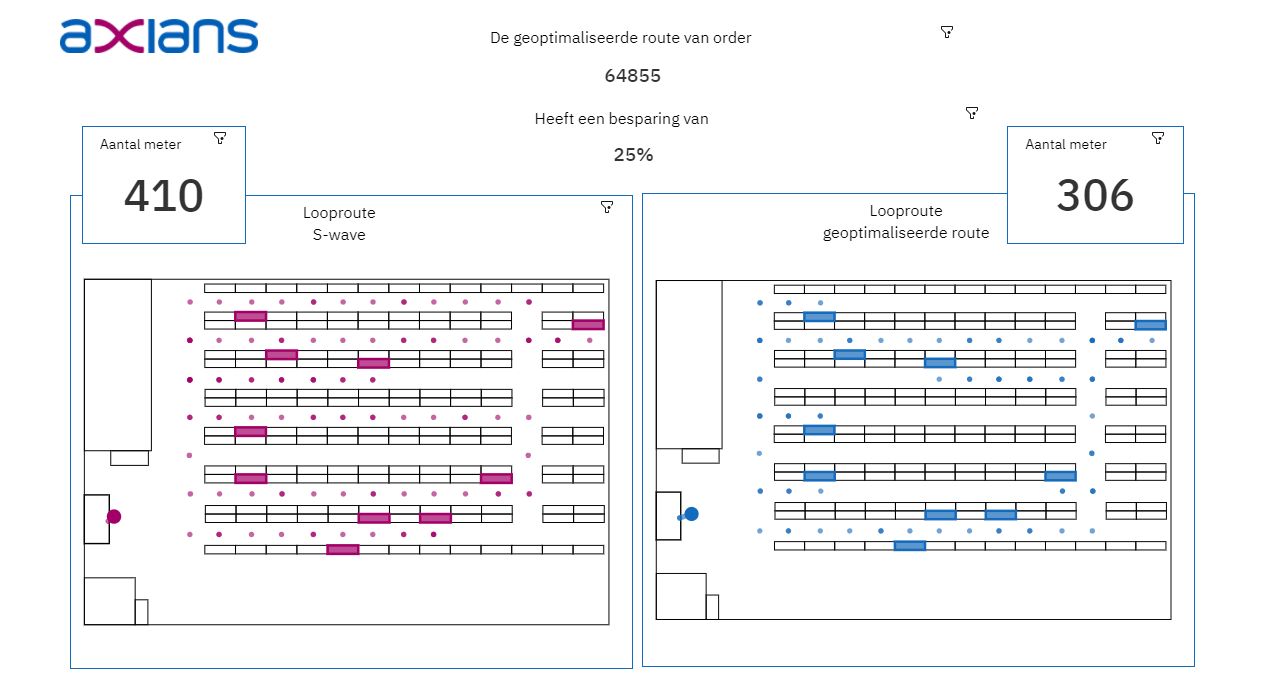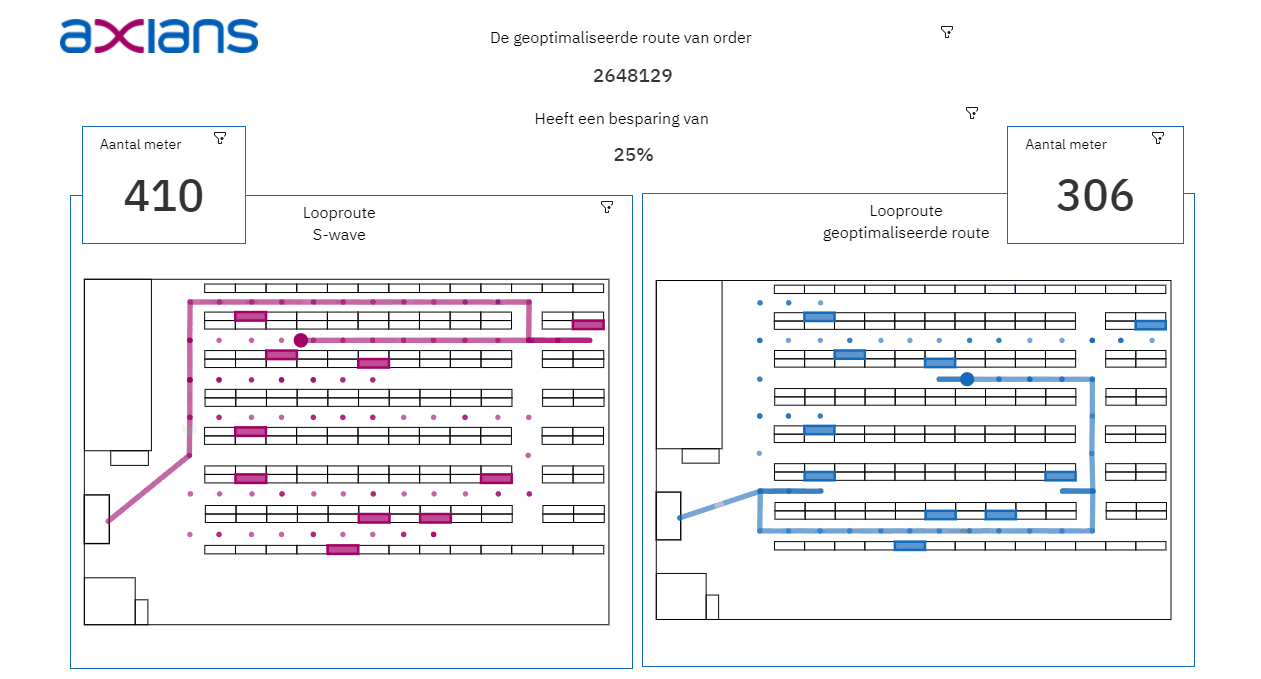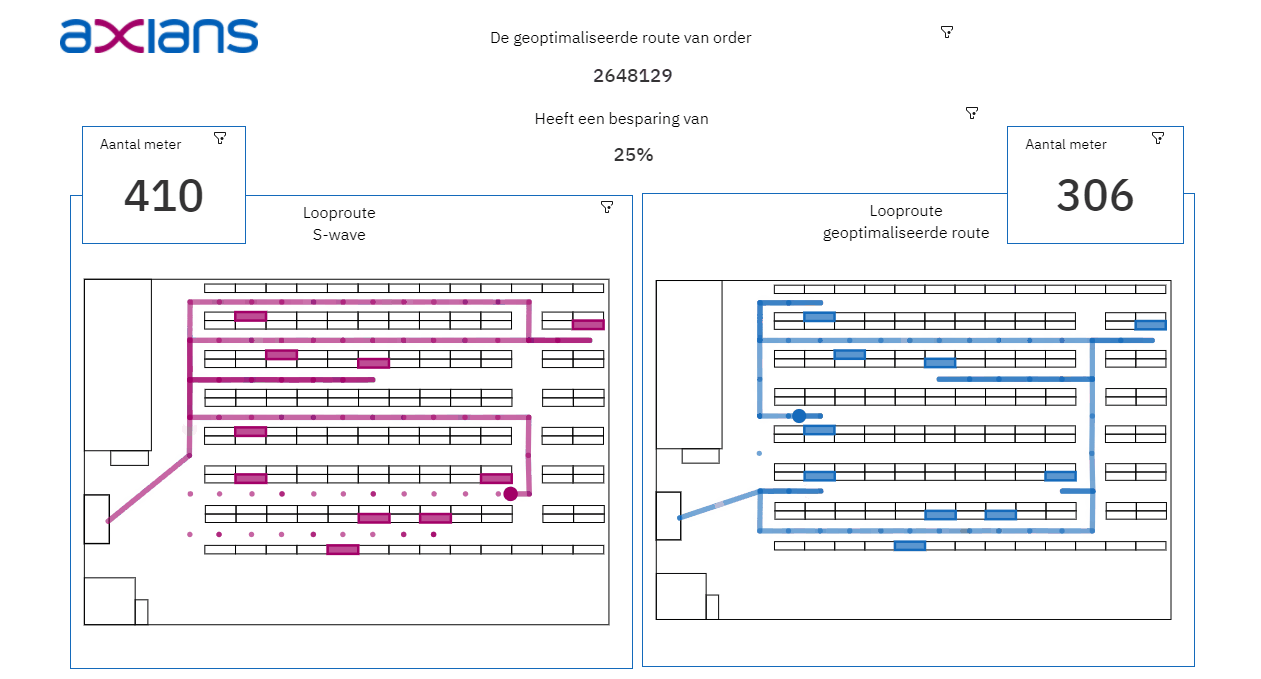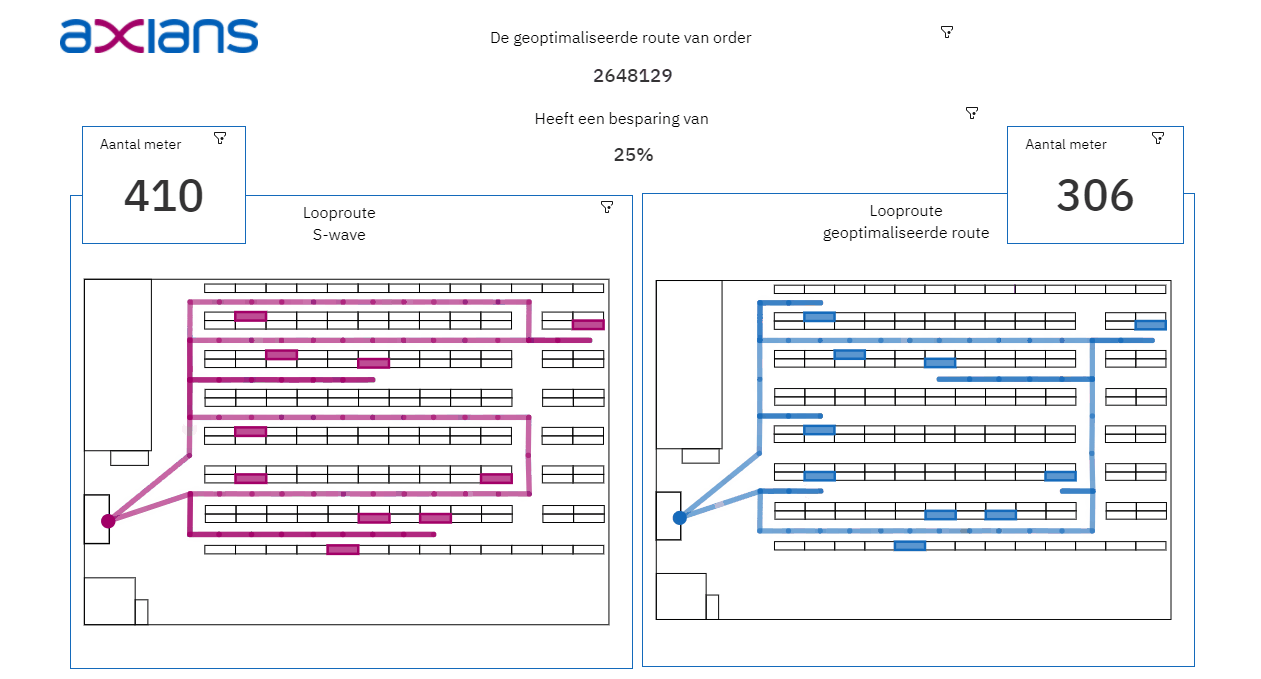
Het analyseren en visualiseren van de opgeslagen data: de uitkomsten van het algoritme en het Data Warehouse is vervolgens input voor een dashboard in Cognos Analytics. In het dashboard wordt de Digital Twin pas echt zichtbaar. Dit Dashboard bestaat onder andere uit algemene informatie over het verschil tussen de huidige looproute en de geoptimaliseerde looproute, de paklijsten voor de orderverzamelaars en een 2D-visualisatie van de looproute in het magazijn.
4. Infuse
Het toepassen van de resultaten uit de vorige stap in de business: door AI toe te passen op de resultaten kan het analytisch proces geautomatiseerd worden. Hierdoor kan het verloop van processen voorspelt worden op basis van de huidige data van het proces. In het geval van een Digital Twin in een magazijn zou het hierbij kunnen gaan om het constant updaten van looproutes en productlocaties wanneer de samenstelling van de huidige bestellingen veranderd.
Waarom Cloud Pak for Data?
Toen wij begonnen met het maken van de Digital Twin, wisten we niet precies welke componenten we precies nodig hadden. Het grote voordeel van Cloud Pak for Data is dat dit ook niet hoeft. We zijn begonnen met het ophalen en combineren van data in Watson Studio. Omdat we gestructureerde data hadden, is er voor gekozen om dit in een IBM Db2 Warehouse op te slaan. Voor het maken van het dashboard zijn we uitgekomen op Cognos Analytics. Cloud pak for data maakt het mogelijk om bij elk individueel project alleen de benodigde componenten te selecteren. De IBM-producten zijn daardoor makkelijk schaalbaar en de performance, en dus kosten, aanpasbaar naar gebruik.
Een voorbeeld hiervan is het Guided Local Search-algoritme in een Jupyter Notebook. Het uitvoeren van dit algoritme werd op een gegeven moment erg zwaar voor de omgeving. Met een paar klikken konden we de performance van het Jupyter Notebook tijdelijk opschalen en zo het algoritme toch uitvoeren. Een ander groot voordeel van Cloud Pak for Data is dat de verschillende producten van IBM makkelijker te combineren zijn binnen één platform. Het Cloud Pak for Data Platform maakt het daardoor mogelijk om binnen een paar weken al een werkend product neer te zetten.
Onze tips & tricks voor een Digital Twin
- Bij een Digital Twin is het van belang dat het eindproduct transparant is. Zo moeten de visualisaties – in ons geval het dashboard – niet alleen laten zien wat de ‘winst’ is van een optimalisatie, maar ook aantonen waar deze ‘winst’ behaald wordt. Hiermee kan de gebruiker overtuigd worden van het succes van de optimalisatie(s).
- Bij het visualiseren van data is het belangrijk om te onthouden dat data niet hetzelfde is als informatie. Het aantal meters van de geoptimaliseerde route zegt niet zo veel, de besparing ten opzichte van de oude route wel. Denk bij het opzetten van een Digital Twin niet alleen na over welke data je beschikbaar hebt, maar ook vooral over wat je te weten wilt komen.
- Ben je nu zelf geïnteresseerd geraakt in een Digital Twin? Vergeet dan niet dat de hier getoonde Digital Twin slechts één van de vele mogelijkheden is. Een Digital Twin hoeft niet persé in de vorm van een dashboard te zijn en kan in veel meer sectoren en processen worden toegepast. Kijk dus goed naar wat de beste vorm is voor jouw businesscase.

Hoe kunnen wij je helpen?
Benieuwd of een Digital Twin jouw organisatie verder kan helpen? Of wil je meer weten over de mogelijkheden van Cloud Pak for Data? Laat je gegevens achter, dan nemen wij snel contact met je op.