
Leer in 10 minuten
- Waarom een centraal datamodel belangrijk is
- Hoe je een centraal datamodel ontwikkelt
- Hoe je daarmee het fundament voor data governance legt
We hebben de laatste tijd veel gepubliceerd over de moderne data-architectuur. Daarbij leggen we steeds de nadruk op het stapsgewijs uitbouwen van de data-architectuur op basis van goed uitgewerkte use cases. Vaak krijg ik dan de vraag: leidt die aanpak niet tot point solutions in plaats van één centraal punt waar alle data samenkomt? Natuurlijk zorgt het werken onder architectuur, met design patterns voor de datastromen, ervoor dat dit niet gebeurt. Maar minstens zo belangrijk hierbij is het werken aan een centraal datamodel. Dat zorgt er bovendien meteen voor dat er een goed fundament voor data governance wordt gelegd.
Waarom is een centraal datamodel zo belangrijk?
Een centraal datamodel legt de verbinding tussen de verschillende bedrijfsonderdelen en -processen. Het zorgt voor samenhang en eenduidigheid. Neem bijvoorbeeld de entiteit ‘klant’. Een klant speelt uiteraard een rol in het verkoopproces, maar ook in het logistieke proces. Net als dat ‘product’ een rol speelt in deze bedrijfsprocessen. Beide entiteiten spelen een rol in verschillende informatiestromen en je wilt dat ze daarbij gebaseerd zijn op dezelfde gegevensverzameling. En dat er een goede, eenduidige definitie van iedere entiteit voorhanden is. Om tot een centraal dataplatform te komen, moet je definities – in een centraal datamodel – op elkaar afstemmen.
Niet alles afstemmen
Te veel afstemmen van definities is echter wel een valkuil voor veel dataprojecten. Maak niet de fout om alles op elkaar af te willen stemmen. Afstemmen van definities kan immers een tijdrovend, complex en soms zelfs frustrerend proces zijn. Beperk je tot de definities van entiteiten die ook daadwerkelijk in meerdere bedrijfsprocessen een rol spelen. Voor het voorbeeld ‘klant’ is dit vrij logisch, maar voor veel andere attributen ligt dat minder voor de hand. Een ‘verzendadres’ speelt een belangrijke rol in het logistieke proces, maar een verkoopafdeling hoef je niet te betrekken bij de definitie van dat attribuut. De ‘gezinssamenstelling’ van een klant is interessant voor de marketingafdeling, maar waarschijnlijk niet voor de administratie. Hetzelfde geldt misschien voor ingewikkelde attributen als ‘productcategorie’ of ‘korting’.
Domeinindeling maakt eigenaarschap duidelijk
Leg afgestemde definities altijd vast in een business glossary en zorg dat gebruikers in de data catalog kunnen zoeken naar definities. Dit draagt bij aan het goed kunnen vinden en begrijpen van data, een belangrijk onderdeel van data governance. Leg daarbij niet alleen de entiteiten vast, maar structureer ze door ze toe te wijzen aan domeinen. Deze domeinen kunnen gerelateerd zijn aan bedrijfsonderdelen, maar dat hoeft zeker niet. Centrale entiteiten als ‘klant’ en ‘product’ kunnen ook een goede basis vormen voor de domeinindeling. Een entiteit behoort altijd tot één domein, maar kan een rol spelen in meerdere domeinen. Bij het vaststellen van de definitie is het van belang om te bepalen tot welk domein die entiteit behoort. Ieder domein wijs je vervolgens toe aan een data-eigenaar en een data steward. Let op, deze toebedeling is dus niet gebaseerd op bronsystemen, maar op domeinen uit het centrale data model!
Verwar het centrale datamodel niet met de exposeerlaag
De rol van het centrale datamodel is dus het verbinden van de verschillende bedrijfsonderdelen in de basis. Hoe bedrijfsonderdelen vervolgens – via de ‘exposeerlaag’ van de data-architectuur – gebruik maken van gegevens is hun eigen verantwoordelijkheid en daar moeten ze ook vrijheid in hebben. Dit geldt overigens niet voor bedrijfsbreed gedefinieerde KPI’s, maar dat is weer een ander verhaal. De noodzaak om informatie te harmoniseren is veel minder groot als die informatie gebaseerd is op dezelfde gegevens. En dat is precies waar het centrale data model voor zorgt.
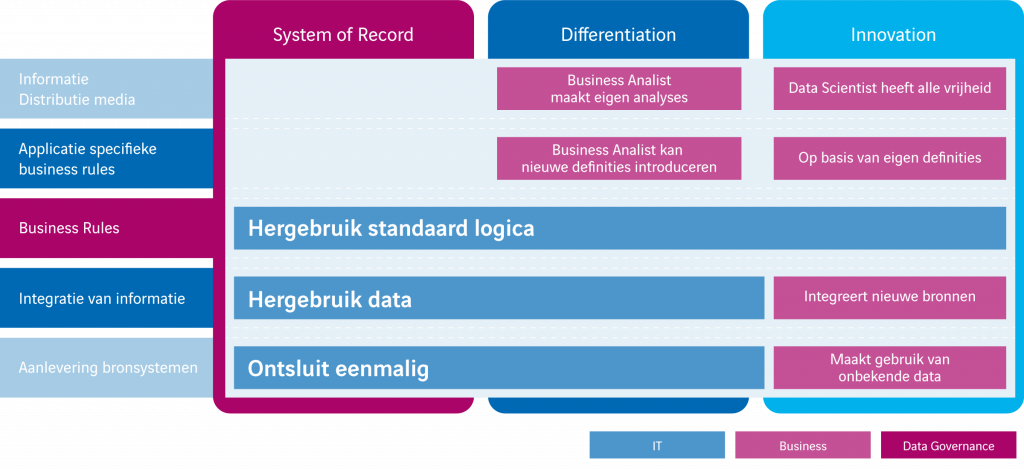
Het centrale datamodel representeert de ‘business rules’ en ‘integratie van informatie’ laag uit bovenstaand PACE layered model.
Manier van modelleren
Hoe ontwikkel je zo’n centraal datamodel? Het model moet in ieder geval een weerspiegeling zijn van het bedrijfsgegevensmodel. Maar zaken als bijvoorbeeld ‘opslag van historie’ en ‘reproduceerbaarheid’ zijn geen onderdeel van het centrale datamodel. Het draait om de samenhang en definities van entiteiten over de verschillende bedrijfsonderdelen en -processen heen. Wel is het verstandig om voornoemde zaken als eigenschap van de entiteit op te slaan in het model.
Modelleer het centrale datamodel als een conceptueel, relationeel model in de derde normaalvorm. Zelf gebruik ik hier graag ERD-software voor, bijvoorbeeld PowerDesigner. In dit soort programma’s kun je veel meer dan alleen modelleren. Je kunt het model uitbreiden met extra eigenschappen en het werk verlichten door het automatiseren van standaardtaken.
Fundament voor data governance
Als je in het centrale datamodel niet alleen entiteiten vastlegt, maar ook definities en zelfs de herkomst van data, maak je meteen een zeer goede start met data governance. Als je goede software gebruikt om het model te bouwen, kun je eenvoudig rapporten definiëren die het model in diverse vormen exporteren. Daarmee heb je direct al de beschikking over een aantal belangrijke data governance capabilities in ruwe vorm:
- Business Glossary
- Data Lineage
- Data Catalog
Door op deze manier te werken, krijg je een beter beeld van de specifieke behoefte binnen jouw organisatie en kan je bij de aanschaf van een echt data governance product de vergelijking tussen tools beter maken. En veel data governance producten kunnen de gegevens die zijn vastgelegd in de ERD-software weer inlezen, dus het gedane werk gaat niet verloren. Bovendien kun je het centrale datamodel als basis gebruiken voor data warehouse automation. Met het direct vastleggen van een centraal datamodel in een ERD-tool, sla je dus drie vliegen in één klap!
Hoever is jouw organisatie met de ontwikkeling van een centraal datamodel?
