
Datakwaliteit meten met machine learning: van gissen en gokken naar voorspellen en detecteren
Datagedreven werken is hot! Bijna ieder bedrijf wil de komende jaren naar een situatie waarin beslissingen op verschillende niveaus in de organisatie niet meer op onderbuikgevoel worden genomen, maar onderbouwd zijn met feiten en voorspellingen. We zijn druk bezig om data te verzamelen, verwerken en analyseren. Daarvoor gebruiken we grote hoeveelheden gestructureerde en ongestructureerde informatie die uit talloze databronnen worden gehaald. En we verwachten eigenlijk dat daar zonder enige problemen correcte informatie uitrolt om objectieve conclusies te kunnen trekken. De praktijk blijkt echter weerbarstiger.
Datakwaliteit is vaak een ondergeschoven kindje, terwijl het een van de belangrijkste voorwaarden is om een succes te maken van datagedreven werken. Ruwe data zit vaak vol met fouten. Dat is onder andere het gevolg van menselijke fouten, meerdere overdrachten en een complexe omgeving van systemen en applicaties. Volgens een recent onderzoek naar datakwaliteit van Harvard Business Review bevat gemiddeld 47% van de recente datasets ten minste één kritieke fout. Dat kunnen verschillende soorten fouten zijn. We zetten een aantal van de meest voorkomende fouten voor je op een rij:
- Duplicaties: dezelfde data staat verspreid over verschillende applicaties en systemen meerdere keren opgeslagen en vaak ook in verschillende versies.
- Onnauwkeurigheid: data bevat fouten en geeft een incorrect beeld van de werkelijkheid.
- Dubbelzinnigheid: spelfouten en misleidende opmaak zorgen ervoor dat de data op verschillende manieren geïnterpreteerd of uitgelegd kan worden.
- Inconsistentie: als je met meerdere databronnen werkt, is de kans groot dat dezelfde informatie in verschillende bronnen niet overeenkomt. Dat komt door verschillen in formaten, eenheden of soms spelling.
Dat onze data zoveel fouten bevat is best een zorgwekkende constatering, vooral als je bedenkt dat slechte datakwaliteit direct invloed heeft op de kwaliteit van datagedreven werken. Zonder kwalitatief goede data zijn planningen, analyses, dashboards en rapportages namelijk weinig waard. Want hoe kun je nieuwe kansen identificeren als data fouten bevat? Hoe toon je aan dat je huidige marketingcampagnes de juiste doelgroep bereiken, als de data waarop je je analyses baseert op verschillende manieren te interpreteren is? Hoe kun je goed bijsturen met financiële forecasts, als je voorspellingen gebaseerd zijn op data met duplicaten erin?
Urgentie neemt toe
De urgentie om over actuele en correcte informatie te beschikken groeit. De hoeveelheid en variëteit aan data in organisaties neemt exponentieel toe, waardoor het steeds lastiger wordt om te achterhalen waar data vandaan komt en hoe bruikbaar die data is. Daarnaast zijn veel organisaties druk bezig om grote hoeveelheden data te migreren naar de cloud. De kans dat je datakwaliteit tijdens dit proces wordt aangetast is behoorlijk groot, waardoor het nog belangrijker wordt om ontbrekende gegevens, waarden en verbroken relaties tussen tabellen, documenten, applicaties en systemen te identificeren. Bovendien zijn er steeds meer initiatieven binnen organisaties die sterk afhankelijk zijn van correcte informatie – denk aan voorspellende AI-modellen of personalisatie van klantcontact. En ook de druk van buitenaf neemt toe om verantwoording af te leggen over het gebruik en de kwaliteit van gegevens.
Als organisaties wél actief bezig zijn om de kwaliteit van hun data te meten, gebeurt dit vaak nog op de traditionele manier. Vooraf wordt bedacht wat er mogelijk mis kan gaan. Vervolgens worden daar manueel regels voor vastgelegd, die ook onderhouden moeten worden. Dat is zeer specialistisch werk dat meestal alleen door IT’ers uitgevoerd kan worden. Door de toenemende complexiteit en variëteit aan databronnen is het haast onmogelijk geworden voor het menselijk brein om alle mogelijke gebreken in de data te voorspellen, ontdekken en definiëren. Bovendien is het up-to-date houden van regels om de datakwaliteit te controleren een enorm tijdrovend, reactief proces.
Datakwaliteit meten met machine learning
Het opmerkelijke is dat organisaties allerlei technologische ontwikkelingen gebruiken om datagedreven te worden, maar dat ze die mogelijkheden links laten liggen voor één van de meest essentiële onderdelen: datakwaliteit. Terwijl er wel oplossingen zijn die je organisatie kunnen helpen om je datakwaliteit op een slimme manier te meten, zoals Collibra Data Quality. Deze tooling maakt gebruik van machine learning om afwijkingen in je data te voorspellen en ontdekken, controles uit te voeren en regels te schrijven die proactief problemen met de datakwaliteit herkennen in datasets, databases en losse bestanden. De algoritmes detecteren zelf onder andere duplicaties, inconsistenties en dubbelzinnigheden.
 Met Collibra Data Quality worden IT én de business samen verantwoordelijk voor datakwaliteit. Het ingebouwde ‘learning framework’ stelt zelf vragen aan verschillende gebruikers over uitzonderingen. Die kunnen ze beoordelen met een uniform scoringssysteem, waarmee het risico van een uitzondering een waarde krijgt. Daarnaast worden de juiste verantwoordelijke medewerkers gewaarschuwd om problemen proactief te identificeren. Door de intuïtieve workflow doorlopen deze gebruikers eenvoudig de juiste stappen om het algoritme te ‘voeden’. Je organisatie is dus niet langer afhankelijk van specialistische kennis, maar IT en de business werken samen om problemen op te lossen. Daarnaast biedt de tooling nog enkele andere handige mogelijkheden:
Met Collibra Data Quality worden IT én de business samen verantwoordelijk voor datakwaliteit. Het ingebouwde ‘learning framework’ stelt zelf vragen aan verschillende gebruikers over uitzonderingen. Die kunnen ze beoordelen met een uniform scoringssysteem, waarmee het risico van een uitzondering een waarde krijgt. Daarnaast worden de juiste verantwoordelijke medewerkers gewaarschuwd om problemen proactief te identificeren. Door de intuïtieve workflow doorlopen deze gebruikers eenvoudig de juiste stappen om het algoritme te ‘voeden’. Je organisatie is dus niet langer afhankelijk van specialistische kennis, maar IT en de business werken samen om problemen op te lossen. Daarnaast biedt de tooling nog enkele andere handige mogelijkheden:
- Afstemming bij het migreren van data: detecteer ontbrekende records, waarden en verbroken relaties tussen tabellen of systemen als er data gemigreerd wordt.
- Horizontale en verticale schaalbaarheid: scan grote en diverse databases, bestanden en streamingdata met parallelle verwerking.
- Gevoelige datadetectie: begrijp automatisch de semantiek van gegevens om gevoelige data te classificeren, labelen en maskeren.
Collibra Data Quality neemt veel handmatige handelingen weg en maakt gebruik van de bestaande kennis, structuren, rollen en processen in de organisatie. Daardoor kunnen bedrijven de complexiteit verminderen en nattevingerwerk bij het beheren van datakwaliteitsregels voorkomen. De betrouwbaarheid van gegevens neemt aantoonbaar toe, waardoor er meer vertrouwen is in de organisatie om strategische beslissingen op basis van data te nemen.
Datakwaliteit staat niet op zichzelf
Datakwaliteit stelt niet alleen eisen aan de data zelf, maar ook aan de manier waarop data wordt beheerd. Daarmee is het een integraal onderdeel van datamanagement en data governance. Dat gaat verder dan technologie. In het eBook ‘Data governance – Het fundament voor datagedreven werken’ leggen we uit hoe je stapsgewijs een goed data governance beleid implementeert waarbij je beleid, processen, organisatie én tooling naadloos op elkaar moet aansluiten.
Collibra is opgebouwd volgens deze visie en biedt een geïntegreerde combinatie van het Collibra platform voor data governance, data management en datakwaliteit. Samen vormen ze de essentiële ingrediënten waarmee je afwijkende waarden kunt meten en fouten kunt detecteren én daar vervolgens ook de juiste actie en de juiste verantwoordelijke in de organisatie aan kunt koppelen. Zij kunnen daarna aan te slag door het probleem te verhelpen of bijvoorbeeld het algoritme te trainen.
Hoe werkt dat in de praktijk?
Laten we eens kijken hoe Collibra Data Quality in de praktijk werkt. De tool beschikt al over een flinke hoeveelheid basiskennis van datakwaliteit, waaronder een set standaardregels om veel voorkomende gebreken te identificeren. We geven een voorbeeld: bij NULL-checks gaat het algoritme na of er eventueel velden zijn waarin geen waarde staat. Er wordt echter ook rekening mee gehouden dat het voor sommige kolommen heel normaal is dat er een percentage lege velden is. Hoe waarschijnlijk dat is, bepaalt het algoritme op basis van statistieken voor elke specifieke dataset. Zo wordt er een verwachtingspatroon gecreëerd, waarbij afwijkingen op de statistieken direct worden gesignaleerd.
Hetzelfde geldt voor MIN-MAX-checks. Hiermee wordt beoordeeld wat de minimum- en maximumwaarden in een kolom meestal zijn. Als een interest rate bijvoorbeeld schommelt tussen de 1% en 5%, dan kan het algoritme bij percentages hoger dan 5% of lager dan 1% een notificatie sturen naar een gebruiker. Zo werkt het eigenlijk voor alle checks. Op basis van statistische analyse wordt er een verwachtingspatroon gecreëerd. Als hier uitzonderingen op zijn, worden er automatisch notificaties gegenereerd.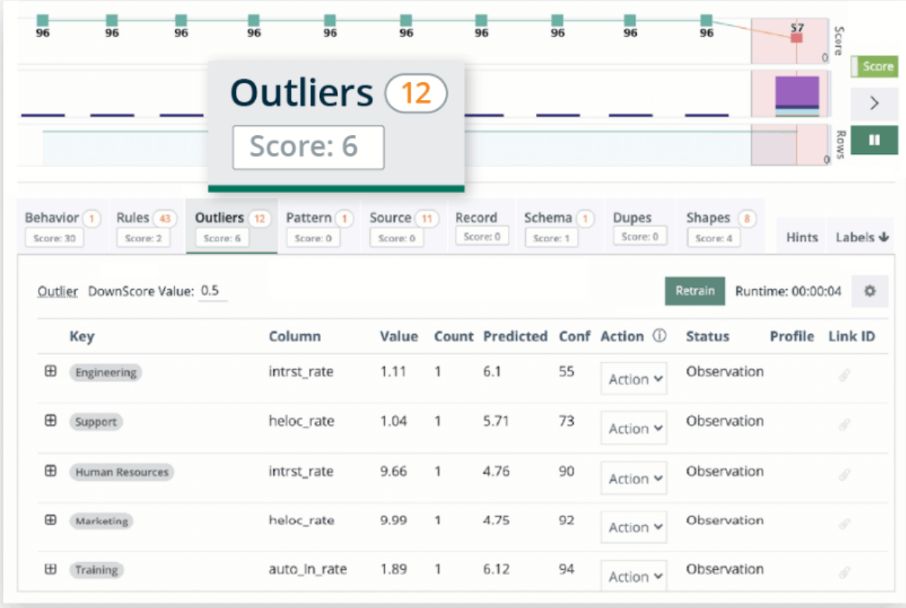
Als organisatie heb je te maken met grote hoeveelheden data. Als je datakwaliteit dus goed wilt meten, is dat met de hand eigenlijk niet te doen. Daar heb je veel rekenkracht voor nodig. Met machine learning kunnen duizenden datasets tegelijkertijd worden geanalyseerd op kwaliteit. Het model wordt steeds slimmer door adaptieve en manuele handelingen uit te voeren, voorstellen te doen en input van gebruikers te verzamelen. Benieuwd hoe het stap voor stap werkt? Bekijk dan eens de demo op de website van Collibra.
Hoeveel tijd zou het jouw organisatie schelen als je fouten in datasets direct kun detecteren?