
Leer in 15 minuten
- Wat gevoelige data nu precies is
- Hoe je gevoelige data kunt identificeren in je bedrijf
- Hoe software je daarbij kan helpen
De druk op organisaties om proactief persoonsgegevens en andere gevoelige data te beschermen is groter dan ooit. Aan de ene kant wordt dit gedreven door regelgeving. Aan de andere kant door het feit dat bedrijven steeds meer concurrentiegevoelige data willen bewaken. Veel CISO’s, business managers en professionals merken echter dat het handmatig vinden en classificeren van sensitieve data niet meer mogelijk is. Ze hebben (geautomatiseerde) oplossingen nodig om gevoelige gegevens in hun bedrijf te lokaliseren, identificeren, beschermen en beheren.
In dit artikel gaan we in op het belang van data identificatie en classificatie en leggen we uit hoe je organisatie kan profiteren van de implementatie van deze twee belangrijke processen in je privacy en security programma. Daarnaast beschrijven we de mogelijkheden om voortdurend geautomatiseerd een ‘gezondheidsscan’ van je omgevingen te doen. Dit is met de hedendaagse datacomplexiteit volgens ons de enige manier om je omgevingen ‘gezond’ te houden.
Consequenties van het stelen of lekken van data
De definitie van gevoelige data kan voor iedere organisatie anders zijn. In essentie is het vertrouwelijke informatie die veilig en buiten het bereik van buitenstaanders moet worden gehouden. Naast het beschermen van data vanuit concurrentieoverwegingen, moet je ook rekening houden met regelgeving(en). Denk bijvoorbeeld aan:
- beschermde gezondheidsinformatie (PHI) zoals gedefinieerd in de HIPAA;
- gegevens van kaarthouders (PCI) zoals gedefinieerd door de Payment Card Industry Data Security Standard (PCI DSS)
- persoonlijke gegevens zoals gedefinieerd door de EU General Data Protection Regulation (GDPR). In Nederland is dit vastgelegd in de Algemene Verordening Persoonsgegevens (AVG).
Organisaties die geautomatiseerde scanning hebben geïmplementeerd konden een datalek sneller identificeren en indammen. Het is echter niet alles of niets. Organisaties met een gedeeltelijke implementatie deden het al significant beter dan bedrijven zonder. Een goede reden dus om in actie te komen of je huidige maatregelen rond data-identificatie te accelereren.
Organisaties die geautomatiseerde scanning hebben geïmplementeerd konden een datalek sneller identificeren en indammen. Het is echter niet alles of niets. Organisaties met een gedeeltelijke implementatie deden het al significant beter dan bedrijven zonder. Een goede reden dus om in actie te komen of je huidige maatregelen rond data-identificatie te accelereren.
Bron: IBM, https://www.ibm.com/reports/data-breach
Wat maakt het beschermen van sensitieve data complex?
Het lekken of stelen van gevoelige informatie leidt tot een vermindering van het klantvertrouwen, een beschadigde reputatie, en soms zelfs tot hoge boetes. Het beschermen van gevoelige gegevens tegen inbreuken en het waarborgen van effectieve privacy is echter niet eenvoudig. Dit komt onder andere door de volgende ontwikkelingen:
- groei – de exponentiële groei van gegevens in vele omgevingen
- dark data – data die je organisatie wel produceert maar niet gebruikt, en ‘je weet niet wat je niet weet’
- data democratization en self-service – iedereen in de organisatie kan data gebruiken
- regel apathie – door een wirwar aan regels neemt compliance af
Dit alles heeft natuurlijk met de voortschrijdende digitalisering te maken. Maar ook in traditionele databases kan het fout gaan. Wat gebeurt er als een helpdeskmedewerker persoonlijke informatie verwerkt in een vrij tekstveld. Hoe houd je dit zonder automatisering van data-identificatie onder controle?
Effectieve data-identificatie en bescherming
Hoe pak je dat dan aan, het identificeren en beschermen van gevoelige data? Door 5 stappen te doorlopen die zorgen voor een passende bescherming van data:
- identificeer je kroonjuwelen – bepaal wat voor jouw organisatie sensitieve data zijn
- data-identificatie – ontdek waar die data is opgeslagen
- data classificatie – classificeer de gevonden data
- bescherming – bescherm je sensitieve data, bijvoorbeeld door encryptie of data masking
- optimaliseer – monitor en optimaliseer je aanpak
In dit artikel gaan we in op de eerste drie punten, en dan met name het identificeren van gevoelige data, en waar deze is opgeslagen. In een volgend artikel komen we terug op de bescherming van die data.
Wat is data-identificatie en data classificatie
Data-identificatie en dataclassificatie zijn twee afzonderlijke processen in een omvattende aanpak. Ze gaan echter wel hand in hand.
Data-identificatie is het proces waarbij je hele omgeving wordt gescand op de aanwezigheid van sensitieve data. Dit betreft zowel gestructureerde als ongestructureerde gegevens en de data-uitwisseling met andere partijen. Dit scannen beslaat zowel je on-premise omgeving als je cloud omgevingen.
Dataclassificatie is het proces van het identificeren van de soorten gegevens en het vervolgens taggen van die gegevens. Doel is om deze in categorieën in te delen op basis van bestandstype, inhoud en andere metagegevens.
Wat levert data identificatie en classificatie je op?
De combinatie van (geautomatiseerde) data-identificatie en classificatie kan je organisatie helpen een reeks voordelen op het gebied van gegevensbeveiliging te realiseren.
- voortdurend en up to date inzicht in je sensitieve gegevens
- focus op je meest kwetsbare gebieden
- kosten besparen door ‘duplicate’ data te verminderen
- voldoen aan wet- en regelgeving;
- maximale flexibiliteit bieden aan gebruikers binnen de regelgeving
Waarom worstelen bedrijven met data identificatie en classificatie?
Binnen de meeste bedrijven is het IT-landschap zo ontwikkeld dat het bijna onmogelijk is geworden handmatig sensitieve data te vinden en te classificeren.
Bedrijven hebben enorme hoeveelheden – en verschillende soorten – gegevens die allemaal moeten worden gevolgd en geclassificeerd in een complexe architectuur. Om het nog moeilijker te maken veranderen gegevens voortdurend en verplaatsen ze zich, ontwikkelt de regelgeving zich en implementeren bedrijven voortdurend nieuwe technologieën en systemen.
Als gevolg hiervan hebben veel organisaties gewoon niet de tijd, middelen en expertise om handmatig alle omgevingen te scannen en data te classificeren. Dat is waar een data-identificatie en classificatie platform, zoals PK Discover, om de hoek komt kijken. Bedrijven kunnen hiermee controle krijgen over hun gegevens en hun data beschermingsstrategie drastisch verbeteren.
PKWare PK Discover platform
In 2020 heeft PKWare Dataguise overgenomen en haar positie als leider op het gebied van security en privacy verder versterkt. Wereldwijd vertrouwen veel toonaangevende brands op de producten van PKware om hun effectiviteit te verbeteren ten aanzien van data compliance en innovatie.
PKWare is een van de weinige leveranciers die zowel beveiligings- als privacymogelijkheden combineert in één software oplossing. Bovendien ondersteunt het product een breder scala aan gegevensbronnen dan de meeste concurrenten. Als je veel verschillende omgevingen hebt, is dit interessant. Je wilt immers graag één enkele oplossing voor je hele IT-omgeving. Daarnaast is PKWare een van de weinige leveranciers die machine learning implementeert om het aantal valse positieven dat kan optreden bij het scannen van gevoelige gegevens te verminderen. Zo wordt veel handmatig corrigeren na het automatisch scannen voorkomen.
PK Discover is het kernproduct van PKWare. PK Discover is zowel beschikbaar on-premise als in de cloud (AWS, Azure en GCP). PK Discover kan scannen op gevoelige elementen in gestructureerde en ongestructureerde databronnen en optioneel die gegevens maskeren of versleutelen. Organisaties kunnen ook de toegang tot de gevoelige gegevens monitoren met behulp van PK Discover.
Wat kun je met PK Discover doen?
PKWare is oorspronkelijk begonnen met de maskering van statische gegevens in meer traditionele gegevensbronnen, zoals Oracle en SQL Server. Inmiddels zijn de mogelijkheden uitgebreid naar (big data) bronnen als Hadoop, MongoDB, Hive en HBase, evenals cloud omgevingen (Amazon S3, RDS en Azure BLOB) en Data Lake opslag (Couchbase- en Cassandra).
PK Discover ondersteunt ook ongestructureerde bronnen zoals Windows- en Linux-bestanden, Microsoft Office, SharePoint en Salesforce. Wat begon met het identificeren en maskeren van gevoelige gegevens omvat nu bovendien encryptie/decryptie en uitgebreide rapportage.
Hoe werkt PK Discover?
PK Discover werkt met gestructureerde, semi-gestructureerde en ongestructureerde gegevens en benadert deze met een scala aan technieken, zoals:
- patroonherkenning
- regular expressions
- proximity matching
- natural language processing
- machine learning
Een uitdaging bij het scannen naar gevoelige data is dat je veel valse meldingen kunt krijgen. Hierdoor heb je alsnog veel handmatig werk te doen. PKWare heeft dit geadresseerd door machine learning in te bouwen in zijn producten. De software ‘leert’ van voorbeeldgegevens of uit voorbeelden van valse positieven. Hierdoor neemt het aantal valse meldingen snel af als het product vaker wordt gebruikt.
Wat als gevoelige data geindentificeerd moet worden, bepalen de policies zoals die gedefinieerd zijn in het platform. Er zijn al allerlei standaard policies voorgeprogrammeerd. Deze kunnen al veel sensitieve data vinden en classificeren. Er kunnen echter ook specifieke wensen zijn binnen een bedrijf. Je kunt de bijbehorende policies dan zelf definiëren en toevoegen.

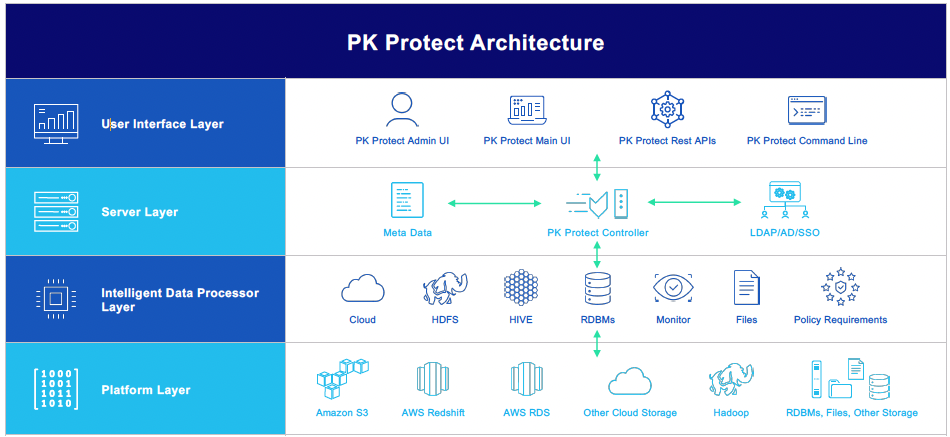
PK Discover architectuur
De architectuur van PK Discover bestaat uit 4 lagen:
- De gebruikersinterface: tools die door de eindgebruiker worden gebruikt om toegang te krijgen tot PK Discover. Dit omvat een browser gebaseerde gebruikersinterface, DGCL, de PKWare-opdrachtregel en REST-API’s.
- De serverlaag: bevat de PK Discover-server, ook wel de ‘controller’ genoemd, die is gekoppeld aan een metadata database. Op AWS kan dit een Amazon RDS-database zijn. De controller integreert ook met andere systemen, zoals LDAP, Active Directory en standaard Single Sign-On systemen.
- De Intelligent Data Processor Layer: deze bestaat uit een of meer intelligente data processors (IDP’s). Er is één IDP per type target data store. Als je bijvoorbeeld gegevens hebt in Amazon S3 en Amazon Redshift, worden één S3 en één relationeel databasebeheersysteem IDP geïmplementeerd. De controller zelf verwerkt geen gegevens uit de target stores, dat is de taak van de IDP. De controller zelf bevat dus nooit gevoelige gegevens.
- De Target DataStore Layer: Bestaat uit je te scannen datastores, zowel in de cloud als op locatie. PK Discover ondersteunt een breed scala aan target data stores en PKWare breidt de ondersteunde lijst regelmatig uit op basis van verzoeken van klanten.
PK Discover rapportage
Het platform heeft een aantrekkelijke user interface en geeft grafisch, met kleuren en tekst, helder weer waar sensitieve data gevonden wordt.
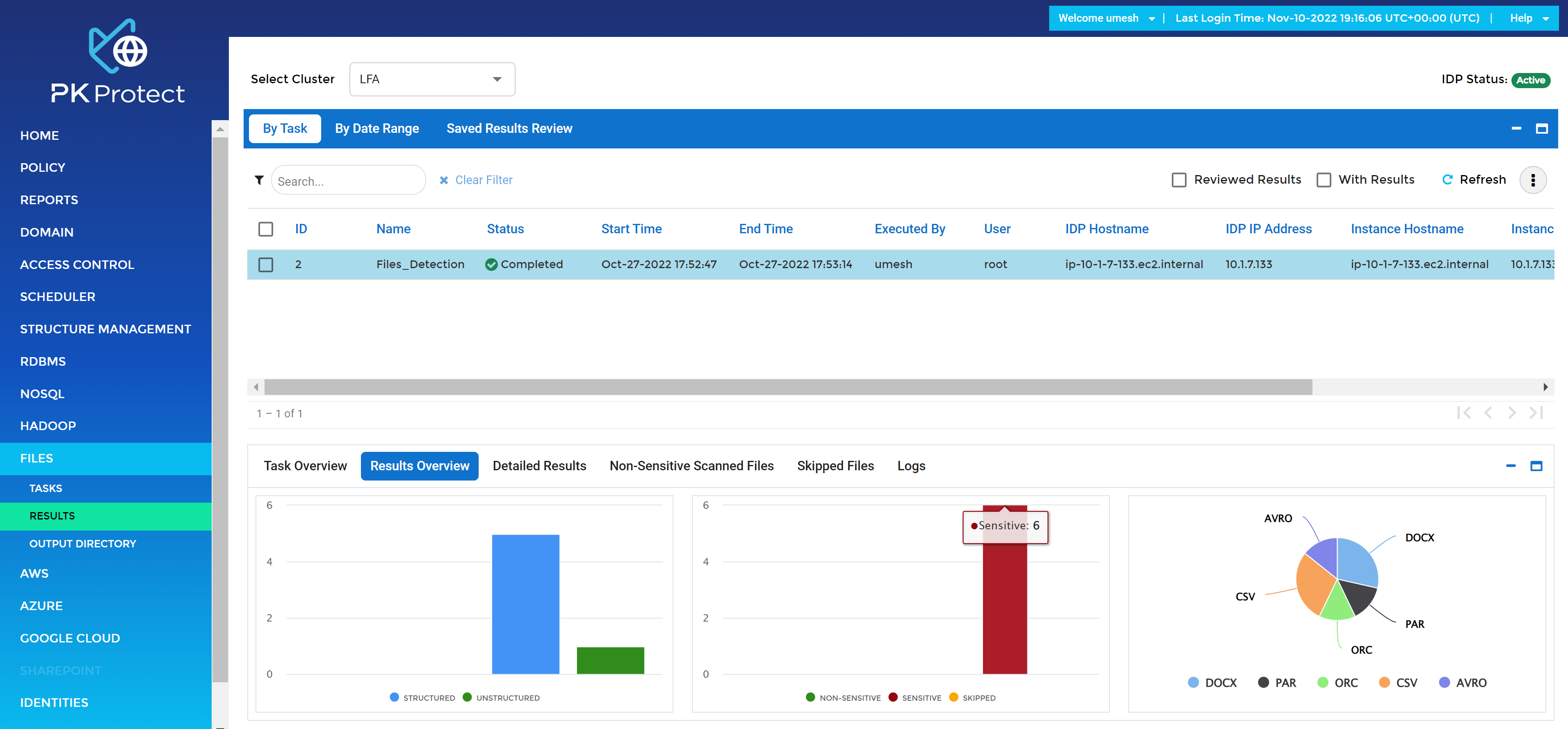
In bovenstaand overzicht staat een voorbeeld van het resultaat van een scan. De grafiek laat zien hoeveel gestructureerde versus ongestructureerde objecten zijn gevonden. De tweede laat zien hoeveel van de gescande objecten gevoelig waren. De laatste grafiek toont een uitsplitsing van de soorten objecten die tijdens de scan zijn gevonden, op basis van bestandstype.
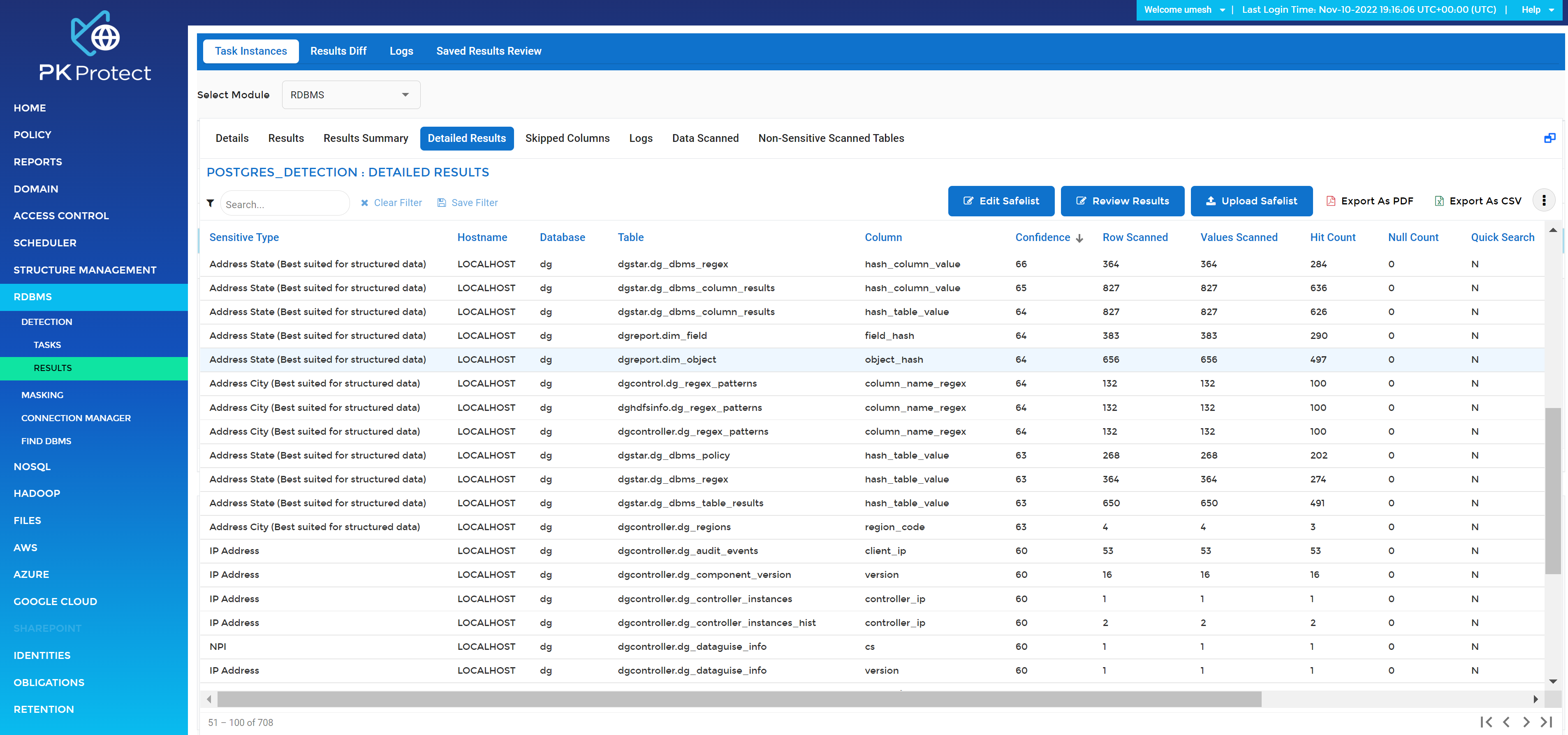
Als je op het tabblad ‘gedetailleerde resultaten’ klikt, krijgt je een overzicht van de gevoelige informatie per object. De resultaten kunnen worden geëxporteerd naar PDF of Excel voor verdere analyse of presentatie.
Conclusie
Data identificatie is geen tool. Het is een proces dat gegevens uit verschillende bronnen evalueert en verzamelt. Vaak wordt het gebruikt om patronen in de gegevens te begrijpen en om de gevoeligheid van de data te bepalen. Om concurrentiegevoelige of persoonlijke data te beschermen, en te voldoen aan wet- en regelgeving, is dit een must.
Een data identificatie platform is een onmisbare set intelligente modules die geautomatiseerde functies en realtime gegevenstoegang biedt, patronen detecteert en gevoelige data identificeert.
In de zakelijke omgeving wordt meer data opgeslagen in een steeds meer divers landschap. Dit maakt het onmogelijk om handmatig data te scannen en te classificeren. Hier biedt de suite PK Discover van PKWare een omvattend security en privacy product. Hiermee kun je je bedrijfsgegevens veilig houden, terwijl je je business maximaal in staat stelt data te gebruiken en systemen te implementeren.
In een volgend artikel gaan we verder in op hoe je de geïdentificeerde gevoelige informatie geautomatiseerd kunt beschermen.
Hoe up-to-date is jouw overzicht van de gevoelige data die is opgeslagen in je on-premise en cloud omgevingen?