
Leer in 11 minuten
- Hoe je als moderne pensioenuitvoerder je informatievoorziening veel efficiënter en persoonlijker inricht
- Waarom de grenzen van je huidige data-architectuur bereikt zijn
- Waarom een moderne data-architectuur op basis van datavirtualisatie jouw organisatie gaat helpen om je grenzen te verleggen
Het pensioenlandschap in Nederland is in beweging. Het pensioenakkoord dat eind 2020 werd gesloten tussen het kabinet en werknemers- en werkgeversorganisaties, is een grote stap in de modernisering van het pensioenstelsel. De nieuwe pensioenregels gaan waarschijnlijk vanaf 1 januari 2023 in, waarna pensioenuitvoerders ruim vier jaar de tijd krijgen om aan de nieuwe wetgeving te voldoen.
Het pensioenakkoord levert veel uitdagingen op voor pensioenuitvoerders. Ze moeten beter inzicht krijgen in de specifieke situatie van individuele deelnemers, zodat ze klantgerichter en persoonlijker kunnen opereren. Data moet bovendien beter ter beschikking worden gesteld, zodat deelnemers op basis daarvan de juiste keuzes kunnen maken. Dat betekent dat pensioenuitvoerders ook steeds meer persoonlijke en gevoelige informatie moeten verzamelen en beheren. Daardoor liggen ze onder een vergrootglas bij instanties zoals de Autoriteit Financiële Markten (AFM) en de Autoriteit Persoonsgegevens (AP). En dan is er ook nog de toenemende concurrentie vanuit enkele IT-bedrijven, die zich op de pensioenmarkt begeven, waardoor de druk toeneemt op de traditionele organisaties om de kosten te verlagen.
Verbeterde informatievoorziening
Kort samengevat dwingt de nieuwe pensioenregeling uitvoerders om hun informatievoorziening veel efficiënter en persoonlijker in te richten. Maar hoe doe je dat? Het is best een lastig eisenpakket om data breder te gaan gebruiken, correct om te gaan met gevoelige data én kosten te moeten verlagen. Vooral als je kijkt naar de huidige situatie van veel pensioenuitvoerders. Binnen de organisatie is vaak een grote hoeveelheid en diversiteit aan data aanwezig. Denk aan (persoons)gegevens van deelnemers, vermogensbeheerdata en allerlei data vanuit beleidsadvisering en de bedrijfskritische processen. Data ligt verspreid door de organisatie en dezelfde data is vaak op meerdere plekken beschikbaar en ligt in een grote verscheidenheid aan technologieën opgeslagen. Dat maakt het lastig om data snel, gecontroleerd en in grotere volumes beschikbaar te maken voor complexere analyses.
Veel pensioenuitvoerders merken dat de grenzen van hun huidige data-architectuur bereikt zijn. Data wordt in de traditionele data-architecturen meestal gekopieerd, getransformeerd en geïntegreerd in één fysieke database, voordat het wordt aangeboden voor analyse, rapportage en visualisatie. Lekker makkelijk, maar bij de huidige vraag naar data loopt je organisatie qua leversnelheid en datavolumes steeds meer tegen de grenzen van deze aanpak aan. Als gevolg daarvan nemen eindgebruikers het heft in eigen handen. Zo ontstaan er veel olifantenpaadjes en gaat een groot deel van het datagebruik om het dataplatform heen. Dat maakt het steeds lastiger om in controle te blijven over de data en te borgen dat gevoelige data alleen door geautoriseerd personeel wordt gebruikt. Daarnaast neemt het risico toe dat beslissingen genomen worden op basis van de verkeerde data.
Niet meer eindeloos data repliceren
De oplossing ligt bij een flexibele data-architectuur. Of beter gezegd: een moderne data-architectuur. In essentie gaat het uiteraard nog steeds om data op de juiste plek beschikbaar stellen, op het juiste moment en in de juiste vorm. Maar met een moderne data-architectuur kun je grote datavolumes, verspreid over een steeds complexer IT-landschap, veel eenvoudiger beheren. Zo kun je sneller voldoen aan de vraag vanuit deelnemers, partners, wet- en regelgevers, stakeholders en je eigen organisatie om data in allerlei vormen en voor verschillende doeleinden beschikbaar te stellen. Daarnaast stelt een moderne data-architectuur je in staat om altijd te voldoen aan de actuele eisen op het gebied van data governance, security en privacy. Vragen over herkomst en gebruik van data kun je snel en betrouwbaar beantwoorden en je kunt data voor bepaalde gebruikersgroepen on-the-fly anonimiseren. Maar hoe onderscheidt de moderne data-architectuur zich van het traditionele data warehouse?
Het antwoord: op twee belangrijke fronten. Zo’n architectuur is allereerst ‘designed for the cloud’ en maakt daarbij optimaal gebruik van alle functionele en technische mogelijkheden van de cloud. Ten tweede wordt er gebruikgemaakt van datavirtualisatie. Dit is een toegangslaag tot alle relevante data binnen en buiten de organisatie, zonder dat die data gekopieerd hoeft te worden. Daarmee maak je het dataminimalisatie principe mogelijk, waardoor het aantal kopieslagen drastisch wordt verlaagd en ook on-demand data tot de mogelijkheden behoord. Zo kun je de kwaliteit van de data makkelijker beheren, weet je beter waar data vandaan komt en wie eigenaar is van die data. Ook loop je minder kans op verkeerd gebruik van data en voorkom je datalekken. Bovendien neemt de snelheid van ontwikkeling toe, kun je de kosten van opslag verlagen en hoef je minder gevoelige data te beheren.
De combinatie van een cloud dataplatform en een datavirtualisatieplatform maakt het bovendien mogelijk veel sneller nieuwe databronnen aan te sluiten en dataservices in te richten, ook voor real time data. Via datavirtualisatie kun je data in allerlei formaten aanbieden, zonder dat die data steeds gedupliceerd moet worden. Het onderliggende cloud dataplatform zorgt ook bij grote datavolumes voor de gewenste performance. Resources kunnen ieder moment worden op- of afgeschaald. Zo kun je meer inzicht krijgen in de actuele situatie van individuele deelnemers door data uit je bedrijfssoftware (bijvoorbeeld CRM en ERP), NoSQL databases en cloudopslag bij elkaar te brengen in één virtuele omgeving.
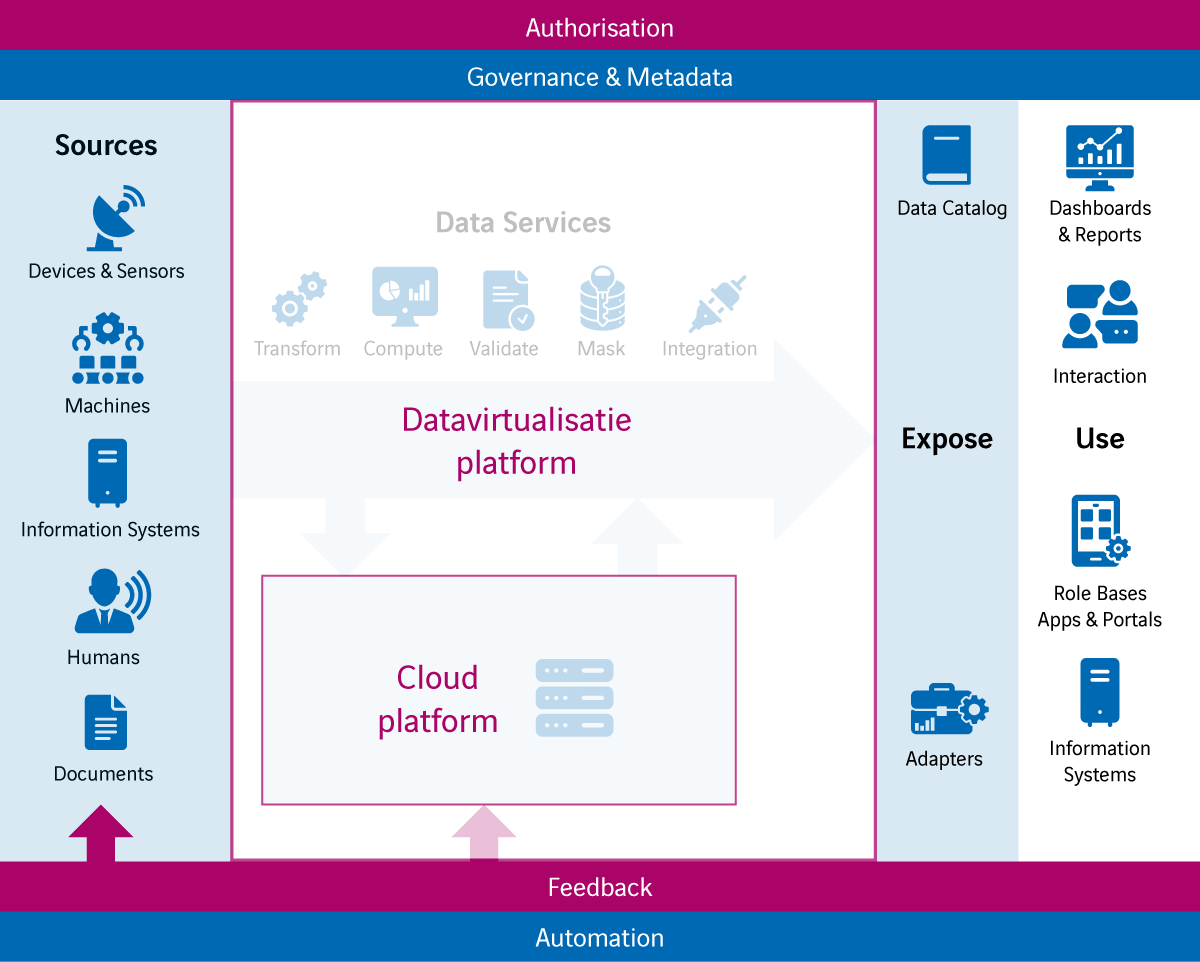
Datavirtualisatie biedt ook voordelen voor de interne informatievoorziening en het leveren van data aan externe stakeholders. Voorheen was het afdoende om rapporten en dashboards te ontwikkelen voor interne gebruikers en rapporten voor externe partijen zoals leveranciers en officiële instanties. Tegenwoordig wil je data veel breder kunnen inzetten. Denk aan vormen zoals self-service BI, waarbij business gebruikers zelf de mogelijkheid hebben om rapporten te ontwikkelen, of data science om te zoeken naar nog onbekende patronen en trends in data waarmee de bedrijfsvoering mogelijk verbeterd kan worden. Of supplier/customer driven BI, waarbij externe partijen zelf bepaalde delen van de data van de organisatie kunnen analyseren. Een datavirtualisatieplatform biedt je de mogelijkheid om dezelfde data via verschillende interfaces te benaderen.
Meer vertrouwen in data en meer controle
Om ervoor te zorgen dat je gebruikers ook de juiste data kunnen vinden, beschikt een datavirtualisatieplatform over een zogenoemde data catalog. Daarin is precies te herleiden welke data er is, wat die precies betekent en waar die vandaan komt. Dit maakt het niet alleen makkelijker om data te vinden voor gebruikers, maar zorgt ook voor meer vertrouwen in de data omdat de herkomst duidelijk is.
Je wilt echter voorkomen dat er incorrect omgegaan wordt met alle data in je organisatie. Dat is met een datavirtualisatieplatform erg eenvoudig, omdat je vanuit een toegangslaag werkt en dus op één centrale plek al het gebruik registreert. Door deze slimme vorm van audit logging weet je precies wie er allemaal gebruikmaakt van bepaalde data. Binnen een oogopslag kun je controleren of er geen ongeautoriseerd gebruik van data wordt gemaakt. Uiteraard moet bepaalde data per definitie afgeschermd worden of alleen beschikbaar zijn voor bepaalde groepen. Een datavirtualisatie platform biedt een breed scala aan autorisatiemogelijkheden en past die on-the-fly toe. Op die manier kan iedereen naar dezelfde dataset kijken, maar wel met de autorisaties die horen bij zijn of haar bevoegdheid.
Hybride aanpak
Wordt de complete data-architectuur dan altijd virtueel ingevuld? Wordt alle data on-demand uit alle bronnen geïntegreerd en geanalyseerd? Voor sommige vraagstukken is dit wenselijk en ook mogelijk. In andere gevallen zijn de volumes te groot, zijn databronnen te traag of behouden ze niet alle data die noodzakelijk is. In dat geval werkt een hybride aanpak – gebruikmakend van datavirtualisatie en de fysieke opslag in een centraal cloud dataplatform – beter. Waar het echt niet anders kan, bijvoorbeeld vanwege het opbouwen van historie, hanteer je de aanpak waarbij data fysiek wordt opgeslagen op het cloud dataplatform. In andere gevallen maken je gebruik van datavirtualisatie om gegevensbronnen virtueel te ontsluiten en integreren. Een oplossing zoals Data Virtuality biedt de mogelijkheden om die hybride aanpak slim vorm te geven. Dit product combineert datavirtualisatie met standaard patronen om data snel te kopiëren en historiseren, zodat de hybride aanpak door één toolset wordt ondersteund. Zo kan er snel tussen de twee gewisseld worden, bijvoorbeeld als het datagebruik of de datavolumes veranderen. Daarnaast is er geen exotische kennis nodig, want het product is 100% SQL gebaseerd. Hierdoor blijft de architectuur eenvoudig en kostenefficiënt.
De toekomst van pensioenuitvoering
Datavirtualisatie maakt het mogelijk om een flexibele en gecontroleerde data-architectuur te ontwikkelen, waarmee je data breder kunt gebruiken en aan kunt bieden, correct gebruik van de data kunt borgen en kosten kunt verlagen. Data wordt aangeboden op één centrale plek, maar zonder dat die data ook daadwerkelijk fysiek op die plek aanwezig moet zijn. Alleen als het niet anders kan, wordt data gedupliceerd. Zo kun je de groeiende behoefte ondersteunen binnen en buiten je organisatie om data steeds sneller en op zoveel mogelijk manieren te gebruiken. Zónder dat dit ten koste gaat van belangrijke zaken als security, governance en privacy. Dat is de toekomst van de moderne pensioenuitvoerder. Sterker nog, er zijn al pensioenuitvoerders zoals PGGM die de stap naar de moderne data-architectuur al hebben gezet. De vraag is dus niet of je de stap moet zetten, maar eerder wanneer je van start gaat!
Hoe snel kan jouw organisatie met de huidige data-architectuur voldoen aan de nieuwe wetgeving?