
Leer in 11 minuten
- Wat een datafabric architectuur is
- Wat de nadelen van een datafabric architectuur zijn
- Hoe je met datavirtualisatie een flexibelere datafabric ontwikkelt
De datafabric is een nieuw en veelbesproken data-architectuur die recent aan het firmament verschenen is. Deze architectuur om systemen te integreren biedt een organisatie diverse voordelen. Gartner vat de voordelen samen door te stellen dat een datafabric een datagedreven organisatie ‘frictionless access’ tot alle data biedt.
Maar de architectuur kent ook nadelen. Hij blijkt niet altijd flexibel genoeg om snel veranderingen door te voeren. Ook is het ontwikkelen ervan tijdrovend. Dit artikel beschrijft de voordelen van het flexibelere alternatief: de logical datafabric. Organisaties die in de datafabric architectuur geïnteresseerd zijn adviseer ik absoluut de logical datafabric variant in detail te bestuderen.
Ted Codd, de grondlegger van het relationele model voor databases, wat op zich weer de basis was voor de bekende databasetaal SQL, schreef in juni 1972 in zijn baanbrekende artikel ‘A Relational Model of Data for Large Shared Data banks’ het volgende “Future users of large data banks must be protected from having to know how the data is organized […] application programs should remain unaffected when the internal representation of data is changed …”
Wat Codd hiermee bedoelde is dat in een systeem de applicatielaag en dataopslaglaag gescheiden moeten zijn, zodat veranderingen in de ene laag niet altijd geforceerd leiden tot veranderingen in de andere laag. Ofwel, die ontkoppeling leidt tot flexibiliteit. Later kende hij een naam toe aan dit principe: het data independence objective. David Parnas, een andere guru, beschreef in dezelfde periode in zijn artikel ‘On the Criteria To Be Used in Decomposing Systems into Modules’ een vergelijkbaar principe wat hij noemde information hiding. Zijn advies was hetzelfde, ontkoppel de applicatielaag van de dataopslaglaag. De termen die zij gebruikten hanteren we momenteel niet meer. Nu zouden we termen hanteren als abstractie en encapsulatie.
Ontkoppelingslaag
De datafabric is een architectuur waar deze ontkoppeling centraal staat. Simpelweg, de datafabric is een ontkoppelingslaag (ofwel abstractielaag) tussen dataconsumenten die data nodig hebben (zoals dashboards, rapporten, mobile apps, websites, portals en transactionele applicaties) en dataproducenten die data opslaan (zoals databases, on-prem applicaties, cloud applicaties en bestanden); zie figuur 1. Deze abstractielaag is opgebouwd uit vele services die verbergen hoe en waar de data ligt opgeslagen. Als dataconsumenten data nodig hebben, dan roepen ze een service van de datafabric aan. Hetzelfde geldt als ze data willen invoeren of wijzigen, ook dat verloopt via services. De services verstoppen dus bijvoorbeeld dat data in een SAP-systeem ligt opgeslagen, in een JSON-bestand of in een SQL-database en of die data lokaal of ergens in een public cloud ligt opgeslagen.
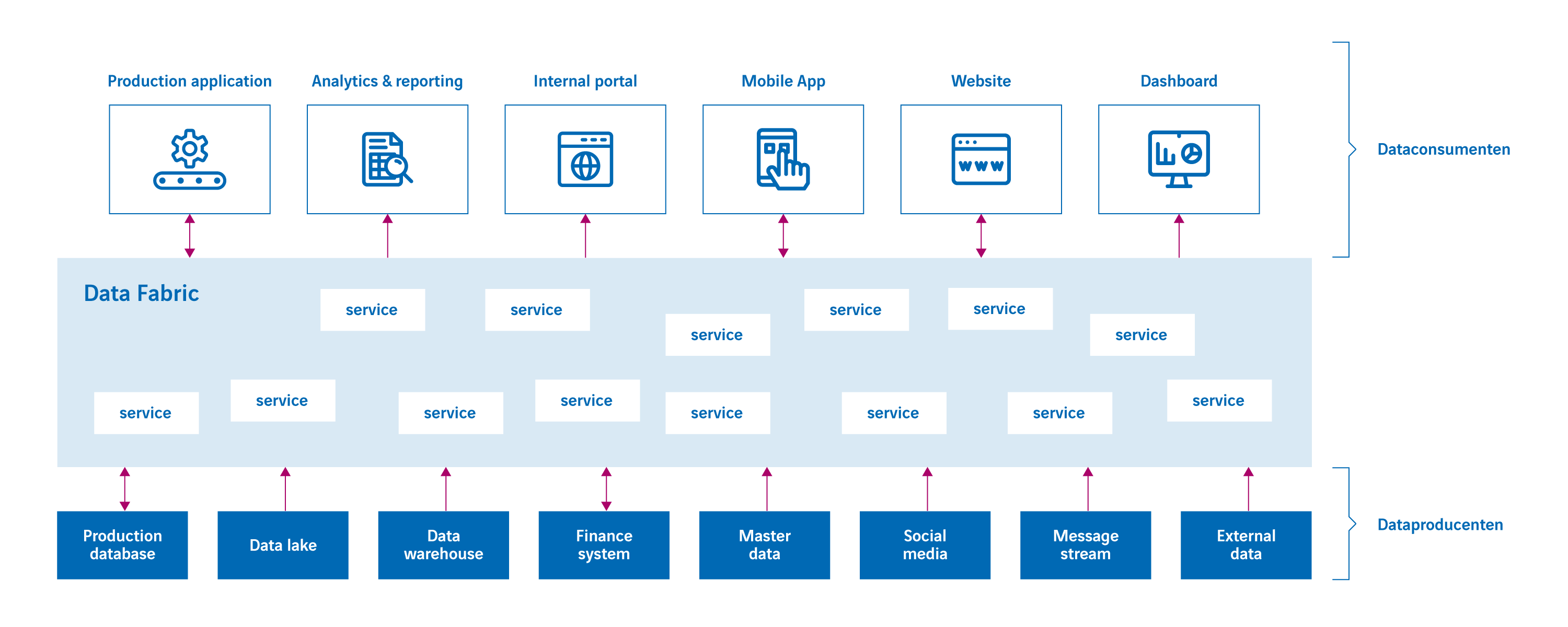
Figuur 1: Algemeen overzicht van de datafabric architectuur.
Complexe services
Services kunnen complex zijn. Bijvoorbeeld, een service waarmee het telefoonnummer van een klant gewijzigd kan worden, moet dat nummer misschien in vijf verschillende systemen bijwerken en zorgen dat de wijzigingen consistent uitgevoerd worden. Een ander voorbeeld is een service waarmee een 360 graden beeld van een patiënt opgevraagd kan worden. Die data bestaat uit medicatiegegevens, adresgegevens, X-ray foto’s en doktersverslagen die uit allerlei systemen opgehaald en samengevoegd moeten worden. Het samenvoegen van data uit meerdere systemen op zich kan al zeer complex zijn. Dit geldt zeker als codes niet afgestemd zijn, sleutelwaardes verschillen en de data mogelijk fouten bevat. In feite is de logica die hiervoor nodig is vergelijkbaar met de logica die in ETL-programma’s ontwikkeld moet worden. Die kan ook zeer complex zijn.
De services van een datafabric zijn niet ‘klein’. Een service om bijvoorbeeld het aantal dagen tussen twee datums te berekenen is te klein. Datafabric services bewerken of bevragen over het algemeen bedrijfsobjecten, zoals een klant, product, bestelling of patiënt.
Er bestaat momenteel de neiging om services te ontwikkelen met behulp van low-level programmeertalen als C#, Java en Python. Dit betekent dat ontwikkelaars bekend moeten zijn met de verschillende technologieën waarmee de dataproducenten ontwikkeld zijn. Ze moeten de interfaces en talen in detail kennen. Veel applicaties hebben allemaal hun eigen proprietary interface. Als een service data uit verschillende dataproducenten moet opvragen die allemaal een andere taal spreken, moeten de ontwikkelaars al die talen kennen en moeten ze ook weten hoe die data geïntegreerd kan worden.
Als services inderdaad dataproducenten direct benaderen, dan is het later vervangen van de technologie van die dataproducenten door een andere een serieus migratieproject. Grote stukken code moeten dan herschreven worden. In dit geval zijn de dataconsumenten wel van de dataproducenten gescheiden, maar tussen de services zelf en de dataproducenten bestaat er geen ontkoppeling. De services zullen de flexibiliteit van het gehele systeem verminderen.
De ontwikkelaars van services kunnen trouwens niet volstaan met te weten hoe de dataproducenten benaderd moeten worden, maar moeten ook weten wat de meest efficiënte manier is om de data te bewerken of op te halen. En als ze de meest efficiënte manier gevonden hebben, kan het zijn dat als de workload verandert of de kwantitatieve karakterieken van de data veranderen, de code aangepast moet worden.
Een andere uitdaging is dat analytische services waarmee data opgevraagd kan worden, ook in staat moeten zijn om ad-hoc vragen te beantwoorden. Denk hierbij aan vragen als ‘Geef de omzetcijfers van de afgelopen tien maanden uitgesplitst naar regio’. Analytische services hoeven niet beperkt te zijn tot vooraf gedefinieerde, statische vragen. Het ontwikkelen van dit soort services is ingewikkeld omdat de service in feite query optimalisatie moet uitvoeren. Dit is niet eenvoudig om zelf te programmeren, zeker als het gedistribueerde query’s betreft. Het zelf programmeren van query optimalisatie is sterk af te raden.
Dit alles betekent niet dat de datafabric een slechte architectuur is, maar dat de flexibiliteit beperkt is.
Flexibeler alternatief
Het verleden heeft uitgewezen dat voor bestaande architecturen flexibeler varianten ontwikkeld kunnen worden. Bijvoorbeeld, de logical data warehouse architectuur is een flexibeler alternatief voor de meer klassieke data warehouse architectuur die bestaat uit meerdere databases, zoals data warehouses en datamarts. Hetzelfde geldt voor het logical data lake dat een flexibeler alternatief is voor de originele data lake architectuur die uitgaat van centrale dataopslag ten behoeve van data scientists. Flexibeler betekent dat de productiviteit verhoogd wordt en dat het eenvoudig is om wijzigingen door te voeren. De flexibelere versie van de datafabric architectuur is de logical datafabric.
Ook bij de logical datafabric worden dataconsumenten van -producenten ontkoppeld; zie figuur 2. Het verschil is dat bij deze architectuur de services niet direct de dataproducenten benaderen maar dat zij een datavirtualisatielaag benaderen die de dataproducenten benadert. Hiermee zijn de services ook ontkoppelt van de dataproducenten.
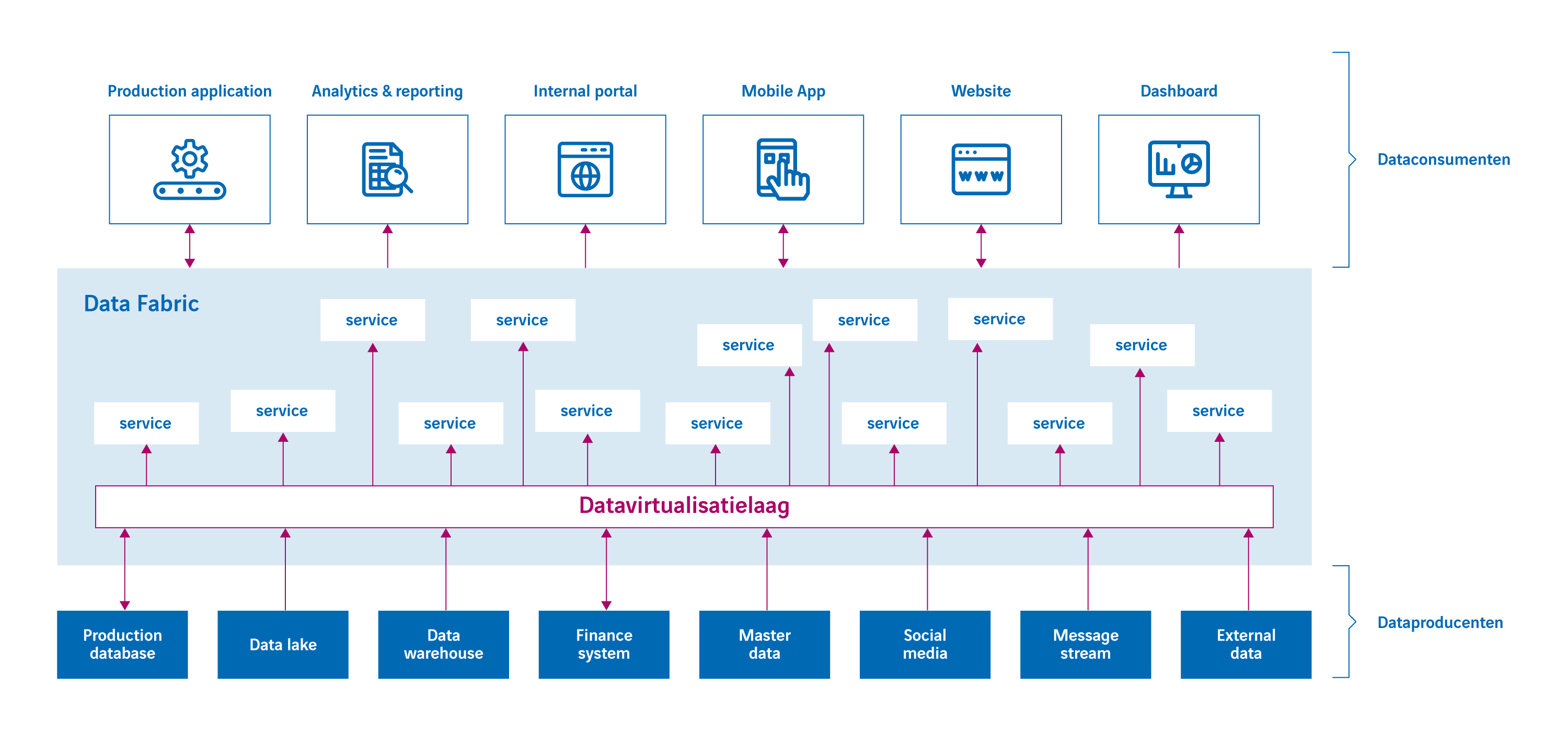
Figuur 2: De logical datafabric met datavirtualisatielaag.
Deze aanpak biedt onder andere de volgende voordelen:
- De logica om de data te benaderen kan in een hogere programmeertaal geschreven worden, namelijk SQL, wat de productiviteit en onderhoudbaarheid drastisch verbetert.
- De datavirtualisatielaag schermt af hoe en waarmee de data opgeslagen is. De ontwikkelaars van de services gebruiken één gestandaardiseerde interface gebruiken om alle data te benaderen.
- De datavirtualisatielaag bevat een query optimizer die weet wat de meest efficiënte manier is om data op te halen. Deze efficiënte wijze wordt niet slechts eenmaal bepaald, maar elke keer opnieuw om de optimalisatie zoveel mogelijk te richten op de op dat moment geldende situatie. Indien data gemigreerd wordt zal de query optimizer zich ook direct aanpassen. Services zelf hoeven hiervoor niet aangepast te worden.
- Als de technologie wijzigt waarmee dataproducenten hun data opslaan, dan past de datavirtualisatielaag zich aan. Ook zullen query’s automatisch anders geoptimaliseerd en verwerkt worden.
- De datavirtualisatielaag kan naast de data ook metadata vastleggen en die ter beschikking stellen aan de services.
- Regels voor beveiliging en privacy die betrekking hebben op het gebruik van de data uit alle dataproducenten kunnen in de datavirtualisatielaag centraal vastgelegd en beheerd worden. Hiervoor hoeft geen code geschreven te worden.
- Het ontwikkelen van analytische services zal vele malen eenvoudiger zijn omdat deze met behulp van de datavirtualisatielaag gedefinieerd worden.
- Figuur 2 doet vermoeden dat er wel altijd services ontwikkeld moeten worden om data via een datavirtualisatielaag op te halen. Dit hoeft echter niet. Een datavirtualisatielaag is in staat om toegang tot de data via een service interface te laten verlopen, waardoor er geen aparte service boven op de datavirtualisatielaag gebouwd hoeft te worden wat de productiviteit verbetert. Dataconsumenten zullen geen verschil bemerken tussen services die gebouwd worden op de datavirtualisatielaag en de services die door de datavirtualisatielaag zelf aangeboden worden.
Conclusie
Ted Codd en David Parnas gaven vijftig jaar geleden al aan dat het belangrijk is om in systemen ontkoppellagen aan te brengen om de flexibiliteit te verhogen. Deze ontkoppeling vindt inderdaad plaats in de datafabric architectuur, maar de logical datafabric gaat één stap verder. De datavirtualisatielaag maakt services van een logical datafabric onafhankelijker van de dataproducenten wat de productiviteit en onderhoudbaarheid verbetert. Hierdoor is de logical datafabric een flexibelere versie van de datafabric met behoudt van alle voordelen. Het advies is dan ook om, als je een datafabric aan het ontwerpen of ontwikkelen bent, het effect te bestuderen dat datavirtualisatie kan hebben als jouw services deze gebruiken om de dataproducenten te benaderen.