
Tunnelvisie, dat zou je het bijna kunnen noemen. De manier waarop we consequent vasthouden aan die ene manier om iedere behoefte aan informatie in te vullen: data kopiëren, transformeren en integreren in één fysieke database. Dat we moeten inleveren op flexibiliteit en snelheid waarmee we informatie opleveren nemen we maar voor lief. Want het is immers de enige manier om fatsoenlijke query performance te krijgen met de enorme hoeveelheden data waar we mee werken. Toch?
Nee, toch niet. Helaas moet ik je teleurstellen, want het kan tegenwoordig echt anders. Ik laat het je graag zien in deze blog post!
Alles met één aanpak?
De traditionele data warehouse aanpak is zo ingeburgerd, dat we niet beter weten dan data meerdere malen te repliceren voordat ze aangeboden worden voor analyse en visualisatie. Het is ons immers ingepeperd dat we niet zonder data warehouse en data marts kunnen. De applicaties en bronsystemen waar we data uit ophalen, zijn immers niet gemaakt voor analyse van data. Ze bevatten vaak niet voldoende historie en – vooral – ze performen niet voldoende. Dus vallen we terug op ‘alles met één aanpak in één datamodel’. Lekker makkelijk. Alleen lopen we qua leversnelheid en data volumes steeds meer tegen de grenzen van deze aanpak aan. Daarom heb ik al meerdere malen betoogd dat een hybride aanpak – gebruikmakend van datavirtualisatie technologie – veel beter werkt. Waar het echt niet anders kan, bijvoorbeeld vanwege het opbouwen van historie, hanteren we de traditionele aanpak. In alle andere gevallen maken we gebruik van datavirtualisatie om gegevensbronnen virtueel te ontsluiten en integreren. Zo ontstaat het logisch data warehouse, het beste van twee werelden.
Slim ophalen
Allereerst zorgen dit soort platformen ervoor dat precies die data worden opgehaald uit de bronsystemen die nodig zijn en geen record meer. Bij datavirtualisatie draait het om het ‘slim ophalen van data’ in plaats van ‘eerst alles op halen en dan filteren en combineren’. Hoe minder data er immers verwerkt moeten worden, hoe sneller het gaat. De query optimizer van het datavirtualisatie platform ontleedt de (SQL) zoekvraag, die vanuit bijvoorbeeld Tableau of Cognos BI komt, in deelselecties. Ieder van deze deelselecties wordt doorgestuurd naar de gegevensbron die de gegevens levert voor dat deel. In Denodo Platform heet dit full aggregation pushdown. De nadruk ligt hier op limiteren en filteren bij het selecteren van gegevens uit de bron. Het ophalen van data gebeurt alleen als dat strikt noodzakelijk is voor de informatievraag. Omdat voor veel gebruikersvragen vaak geen grote hoeveelheden data nodig zijn, kost het ophalen van de deelselecties uit de gegevensbronnen en deze combineren tot de benodigde set gegevens niet veel tijd.
 Praktijkvoorbeeld
Praktijkvoorbeeld
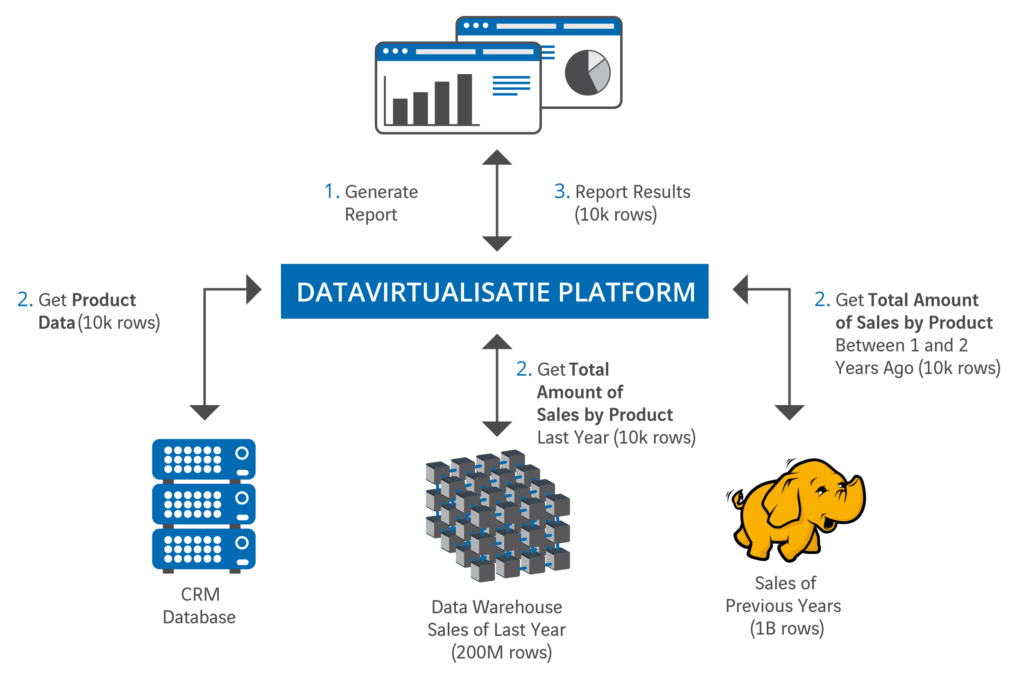
Ik zal het laten zien aan de hand van een praktijkvoorbeeld. We vergelijken de performance van een logisch data warehouse en een fysiek data warehouse bij dezelfde query’s. Beide data warehouses bevatten dezelfde (hoeveelheid) gegevens, alleen hun architectuur is verschillend. Het fysieke data warehouse bestaat uit een enkele database waarin alle, uit de bronsystemen opgehaalde en getransformeerde data is opgeslagen. Het logisch data warehouse daarentegen levert gegevens via een datavirtualisatie laag. Het lijkt één gegevensbron, maar data staan in meerdere bronsystemen en worden ‘on the fly’ opgehaald. Het fysieke data warehouse, op een IBM PureData (voorheen Netezza) appliance, bevat 292,4 miljoen records. Evenveel als in de drie separate databases van het logisch data warehouse.
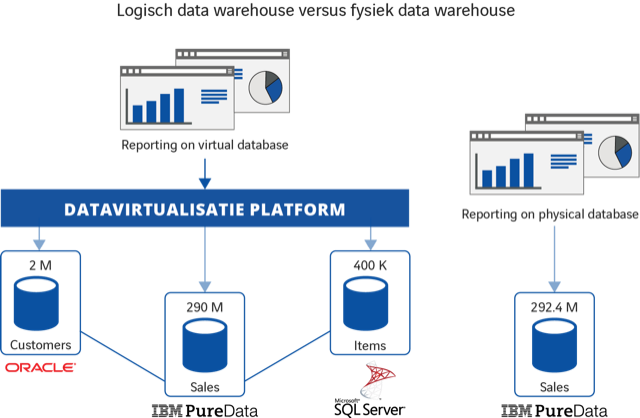
Op beide data warehouses (fysiek en logisch) worden dezelfde query’s losgelaten om de performance te meten. Als we de resultaten hiervan vergelijken, zien we dat de performance tussen de twee oplossingen niet significant verschillend is:

Afhankelijk van de zoekvraag die wordt gesteld wordt door het datavirtualisatie platform de meest efficiënte methode gekozen voor het snel ophalen en combineren van de benodigde gegevens. Hoewel je de gebruikte methode kunt beïnvloeden, blijkt dat in de praktijk nagenoeg niet nodig te zijn.
Conclusie
Inderdaad. De conclusie is: ‘stop met het consequent, maar ondoordacht kopiëren van data naar een fysiek data warehouse om performance redenen!’ Ook met een logisch data warehouse, waarbij gegevensbronnen virtueel worden aangesloten, zijn prima performance resultaten te behalen. Zonder in te leveren op performance, levert de inzet van datavirtualisatie je wel flexibiliteit, real-time beschikbaarheid van data, een veel eenvoudiger architectuur, eenvoud in beheer en een flink hogere leversnelheid. Dus stop met eindeloos ETL’n en bekijk per gegevensbron wat de beste aanpak is: fysiek of virtueel integreren. De huidige generatie datavirtualisatie platformen als Denodo leveren alle functionaliteit die je daarvoor nodig hebt in één geïntegreerd platform.
Je data warehouse wordt dan een multi-platform omgeving. Het traditionele, relationele data warehouse blijft voortbestaan, maar alleen voor die data die dat absoluut vereisen. Andere gegevens sluit je veel eenvoudiger en sneller aan met datavirtualisatie. Zonder verlies van performance!
Hier vind je de onderbouwing van de cijfers in deze post.
Hier vind je meer achtergrond over performance in verschillende data virtualisatie scenario’s.
Overtuigd om ook te gaan experimenteren met een datavirtualisatieplatform?