
Leer in 10 minuten
- Waarom je zou moeten nadenken over een nieuwe data-architectuur
- Waarom je geen technologie-onafhankelijke architectuur meer kunt ontwikkelen
- Hoe een unified data delivery platform een alles overkoepelende data-architectuur levert
Veel organisaties zijn nieuwe data-architecturen aan het ontwikkelen voor het opslaan, verwerken en analyseren van data. Dit heeft alles te maken met het streven naar een meer datagedreven organisatie, waarin data een invloedrijkere rol gaan spelen bij de bedrijfs- en beslissingsprocessen. Maar hoe moet zo’n nieuwe data-architectuur eruitzien? De uitdaging voor veel organisaties is een architectuur te ontwikkelen die gebruik maakt van alle nieuwe technologieën die de laatste jaren beschikbaar gekomen zijn en, belangrijker, die aan alle huidige en toekomstige informatiebehoeften voldoet, oftewel toekomstbestendig is.
Waarom een nieuwe data-architectuur?
Velen zullen de vraag “Wat is de grootste verandering in de IT-industrie van de afgelopen tien jaar geweest?” beantwoorden met: big data. Maar is dat wel zo? Big data is nog steeds data. Het bestaat uit woorden, codes, getallen, datums, foto’s, video’s en tekst. Met de komst van big data is er geen nieuw datatype bijgekomen. Big data systemen verwerken, registreren en analyseren dezelfde gegevens als oudere IT systemen, het zijn alleen meer gegevens. Om deze enorme hoeveelheden gegevens efficiënt te verwerken is uiteraard nieuwe technologie noodzakelijk. Maar de noodzaak om meer van dezelfde data op te slaan, kan moeilijk als de ‘grootste’ verandering binnen de industrie worden gezien.
De echte grote verandering is gerelateerd aan hoe organisaties met data om willen gaan. Organisaties gebruiken data steeds intensiever, meer wijdverspreid en op veel nieuwe manieren. Ze hebben hun digitale transformatie gestart en zijn op weg om meer als datagedreven organisaties te opereren. Dit heeft geleid tot een werkelijk grote verandering: het datagebruik is veranderd. Traditionele vormen van datagebruik, zoals rapportages en dashboards, zijn niet meer toereikend. Er is een groeiende behoefte om de investering in data op zoveel mogelijk manieren uit te baten. Het anders gebruiken van big data is dan ook de grootste verandering en niet big data zelf.
Deze verandering van big datagebruik is direct gerelateerd aan het feit dat organisaties inzien wat de potentiële waarde van data is. Langzaam ontstaat het inzicht dat data op zichzelf geen waarde heeft. Het is niet zoals geld. Geld heeft waarde ook al doe je er niets mee. Data daarentegen heeft alleen waarde als je er iets mee doet, als je het gebruikt, als je het inzet.
Veranderingen van datagebruik
Voorheen was het afdoende om rapporten en dashboards te ontwikkelen voor interne gebruikers en rapporten voor externe partijen zoals leveranciers en officiële instanties. Tegenwoordig willen organisaties hun data veel breder inzetten. De volgende vormen van datagebruik worden bijvoorbeeld steeds populairder:
- Service BI: business gebruikers krijgen zelf de mogelijkheid om rapporten te ontwikkelen met daarvoor bestemde producten als Microsoft PowerBI, QlikSense en Tableau.
- Embedded BI: hierbij worden bijvoorbeeld KPI’s binnen operationele applicaties geïmplementeerd.
- Supplier/Customer driven BI: externe partijen kunnen bepaalde delen van de data van de organisatie zelf analyseren.
- Applied AI in Text, Image, Video Analysis: artificial intelligence technieken worden ingezet om slimmere analyses op elk soort data uit te voeren.
- Edge analytics: hierbij worden analyses van data die bijvoorbeeld door sensors geproduceerd wordt, dicht bij de sensoren geanalyseerd, dus voordat die data naar een centraal punt wordt gestuurd voor analyse.
- Data science: zoeken naar nog onbekende patronen en trends in de data waarmee de bedrijfsvoering mogelijk verbeterd kan worden.
Zeker de laatste vorm voor het ontwikkelen van modellen geniet erg veel aandacht. Veel organisaties hebben hiervoor speciaal data scientists in dienst genomen.
Om al deze vormen van datagebruik te kunnen ondersteunen, moeten er geavanceerde systemen ontwikkeld worden. Deze systemen noemen we data delivery systemen. De bestaande data delivery systemen, ontwikkeld voor al deze vormen van datagebruik, zijn echter niet toereikend voor alle vormen van datagebruik. Dit zorgt voor een toenemende behoefte bij organisaties om nieuwe data-architecturen te ontwerpen.
De invloed van technologie op de data-architectuur
Bij de ontwikkeling van data-architecturen gingen we er ooit vanuit dat ze onafhankelijk van technologieën en producten opgezet moesten worden: eerst de data-architectuur bepalen en daarna de bijpassende producten erbij zoeken. Dit was mogelijk doordat veel producten redelijk uitwisselbaar waren. Zo waren veel SQL-producten redelijk vergelijkbaar wat betreft mogelijkheden en performance. Hetzelfde gold voor ETL- en rapportageproducten. Maar dit geldt niet meer. De laatste jaren worden we geconfronteerd met een niet aflatende stroom technologieën voor het verwerken, analyseren en opslaan van gegevens. Denk hierbij aan Hadoop, NoSQL, TranslyticalSQL, GPU-databases, Spark en Kafka. Deze technologieën hebben een grote invloed op dataverwerkende architecturen, zoals data warehouses en streaming applicaties. De belangrijkste reden is dat veel technologieën een zeer unieke interne architectuur hebben en direct bepaalde data-architecturen afdwingen. Dus kunnen we nog wel een technologie onafhankelijke data-architectuur ontwikkelen?
Voorbeelden van producten met een unieke architectuur
Neem als voorbeeld de SQL-databaseserver Snowflake. Deze heeft een interne architectuur die sterk afwijkt van bekende SQL-databaseservers. In feite kan met dit product in één keer een gehele datawarehouse-architectuur, bestaande uit een staging area, een centraal datawarehouse en datamarts, opgebouwd worden. Dus in plaats van drie lagen met databases te ontwerpen en te beheren en de bijbehorende ETL-programma’s te ontwikkelen, vervangt Snowflake al deze databases. Tevens voert het product end-to-end encryptie toe waardoor hiervoor geen aparte producten aangeschaft hoeven te worden of speciale programma’s of procedures ontwikkeld moeten worden. Dit zou voor meer traditionele databaseservers wel nodig zijn geweest.
Een ander voorbeeld is een datavirtualisatie product als Denodo waarmee data-integratie, in tegenstelling tot ETL, on-demand uitgevoerd kan worden. Als een dergelijk data-integratie product wordt geselecteerd in plaats van een ETL-product, dan heeft dat een grote invloed op de uiteindelijke data-architectuur.
Maar ook GPU-gebaseerde databaseservers beïnvloeden de architectuur. Ze zijn in staat met relatief goedkope machines zeer snel bepaalde query’s te verwerken, ook als het veel data behelst. Een voorbeeld van een dergelijk product is de SQL-databaseserver SQream. Dit is echter niet een SQL-databaseserver zoals de meeste andere. SQream is namelijk niet ontwikkeld voor persistentie, maar alleen voor brute query performance. Het is als het ware een datamart-achtige technologie en kan dus niet gebruikt worden voor de implementatie van een centraal datawarehouse.
Invloed van cloud op data-architecturen
Het grote voordeel van het draaien van data delivery systemen in de cloud is ontzorging. Veel zaken waar een organisatie vóór het cloud-tijdperk veel tijd aan moest besteden, worden nu door de cloud-leveranciers afgehandeld. Bijvoorbeeld het zorgen dat de airco in het rekencentrum goed staat afgesteld, dat er op tijd nieuwe schijven aangeschaft en geïnstalleerd worden en dat de database gerepareerd wordt als deze crasht. Het ‘vergroten’ van de omgeving met meer schijfruimte en processing-kracht is in de cloud ook eenvoudiger.
Deze ontzorging door de cloud heeft ook invloed op de data-architectuur. Sommige aspecten zullen geheel anders ingevuld worden als er wel of niet in de cloud gewerkt wordt.
Pas op voor geïsoleerde data delivery systemen
Kortom, de behoefte aan nieuwe data-architecturen is duidelijk. De nieuwe vormen van datagebruik dwingen die nagenoeg af. Helaas kiezen veel organisaties ervoor om voor elke nieuwe vorm van datagebruik een apart data delivery systeem te ontwikkelen. Bijvoorbeeld, een data lake wordt ontwikkeld ter ondersteuning van data science en andere experimentele vormen van analyse. Of, er wordt een apart systeem voor data streaming ontwikkeld met Kafka als basis technologie. De data marketplace wordt een apart data delivery systeem en voor alle Java apps die draaien op mobile devices geldt hetzelfde.
Het grote nadeel van deze aanpak is dat deze data delivery systemen onafhankelijk opgezet worden, terwijl ze wel veel aspecten delen. Ze gebruiken dezelfde bronsystemen en delen ongetwijfeld gebruikers. Bijvoorbeeld, een data scientist heeft klantgegevens uit het ene systeem nodig en facturatiedata uit een ander. Dit betekent dat er in de data lake-omgeving een oplossing geïmplementeerd moet worden waarmee die twee databronnen correct geïntegreerd worden. Tegelijkertijd zijn gebruikers van het datawarehouse misschien ook geïnteresseerd in een rapport waarin die twee bronnen samenkomen. Hier moet dus weer een oplossing voor ontwikkeld worden. En misschien moet voor de Java apps wederom een vergelijkbare oplossing bedacht worden.
Het effect is dat bij de ontwikkeling van elk data delivery systeem het wiel opnieuw uitgevonden wordt. In het vorige voorbeeld wordt dus driemaal een oplossing voor de integratie van klant- en facturatiedata ontwikkeld met waarschijnlijk verschillende technologieën. Dit is verre van efficiënt en het is tevens slecht voor de productiesnelheid en onderhoudbaarheid. Tevens is het een uitdaging om die oplossingen zodanig te ontwikkelen dat ze altijd consistente resultaten geven. Wie gaat garanderen dat de oplossingen consistente antwoorden opleveren en wie garandeert dat een wijziging overal consistent doorgevoerd wordt?
Het is belangrijk dat voor al deze nieuwe vormen van datagebruik een alles overkoepelende data-architectuur, oftewel één geïntegreerde architectuur, ontwikkeld wordt. Eén waarin specificaties één keer geïmplementeerd worden en vele malen hergebruikt kunnen worden. Organisaties moeten op zoek naar een dergelijke architectuur.
Een mogelijk alternatief is het unified data delivery platform (UDDP); zie figuur 1.
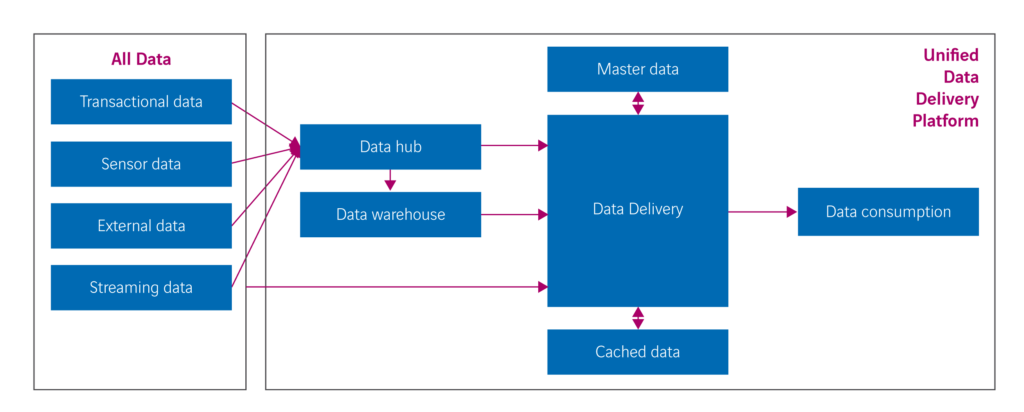
Data in deze data-architectuur wordt gekopieerd naar een datahub, een grote verzamelplaats van alle relevante data ter ondersteuning van veel vormen van datagebruik. Hier wordt, indien nodig, ook historie bijgehouden. Deze datahub bevat de ongewijzigde data. De verantwoordelijkheid voor de kwaliteit en het opschonen van data wordt zoveel mogelijk verplaatst naar de eigenaren van de bronsystemen. Indien data in de datahub toch opgeschoond moet worden, dan wordt een nieuwe versie van de data toegevoegd. Dit kan bijvoorbeeld op een datavault-achtige manier.
Het datawarehouse in het UDDP is nodig om data alvast enigszins te bewerken om bepaalde gebruiksvormen te vergemakkelijken en mogelijk te versnellen. In feite is dit datawarehouse een soort universele datamart. De hoeveelheid bewerkingen die op de data is losgelaten, zal aanzienlijk minder zijn dan bij een klassiek datawarehouse.
Het hart van het UDDP wordt gevormd door de data delivery module. Deze wordt geïmplementeerd met een datavirtualisatie server en is verantwoordelijk voor het ophalen van data uit de bronsystemen, de datahub en het datawarehouse. Tevens is het verantwoordelijk voor het zodanig transformeren, integreren, filteren en aggregeren van de data zodat het precies voldoet aan bepaalde informatiebehoeften. Deze module is tevens verantwoordelijk voor zaken als beveiliging en privacy-aspecten. Binnen deze module wordt replicatie van data tot een minimum beperkt.
Een master database is nodig om precies te weten wat correcte data is, oftewel wat de golden records zijn. De cache database is aanwezig om eventueel tussenresultaten van datatransformaties tijdelijk op te slaan ten behoeve van snelheid of consistentie van rapporten gedurende een bepaalde periode.
Afsluitende opmerkingen
Uiteraard is het UDDP niet de enige denkbare data-architectuur waarmee organisaties het brede scala van datagebruiksvormen op een geïntegreerde manier kan ondersteunen. Het is een alternatief. Wel is het belangrijk dat organisaties naar iets dergelijks op zoek gaan. Het ontwikkelen van geïsoleerde data delivery systemen waarbij het wiel telkens opnieuw uitgevonden wordt, is niet houdbaar. Er moet een geïntegreerde oplossing komen. De technologie is beschikbaar om welke data-architectuur dan ook te ontwikkelen, dus dat kan niet de beperking zijn.
Big data zelf is niet de grootste verandering, maar wel het gegeven dat organisaties veel vormen van datagebruik willen inzetten om meer data-gedreven te worden. Dit vereist een moderne, geïntegreerde en toekomstbestendige data-architectuur. Het bepalen van deze architectuur wordt de komende jaren de uitdaging voor veel organisaties.
Wat zou een unified data delivery platform jouw organisatie kunnen opleveren én besparen?