
Op 28 mei 2018 wordt de General Data Protection Regulation (GDPR) van kracht. Door de nieuwe wetgeving moeten organisaties voldoen aan een strenger eisenpakket om persoonsgegevens beter te beveiligen. In eerdere blogs vertelden we al hoe je in een aantal stappen voldoet aan de GDPR-wetgeving en waarom je met de komst van GDPR minder of doelmatiger data moet verzamelen. Veel organisaties richten zich echter vooral op procedurele maatregelen, maar hebben moeite om ook technisch te voldoen aan de GDPR. In dit artikel leggen we uit hoe datavirtualisatie je daarmee kan helpen.
Flink eisenpakket
Persoonlijke data verspreidt zich razendsnel binnen je organisatie. Bijvoorbeeld als je een e-mail ontvangt met persoonlijke gegevens van een klant. Die e-mail wordt opgeslagen op je e-mailserver en daar wordt weer een back-up en een compliance-kopie van gemaakt. Vervolgens wordt van het compliance-archief ook nog een replica gemaakt. Voor je het weet staan de persoonlijke gegevens van één persoon in tal van systemen, zowel in de cloud als on premise. Met de komst van de GDPR wordt echter van organisaties verwacht dat ze onder andere persoonlijke data adequaat beveiligen, dat ze weten waar data is opgeslagen en wie toegang heeft tot de gegevens en dat ze data direct kunnen verwijderen en anonimiseren.
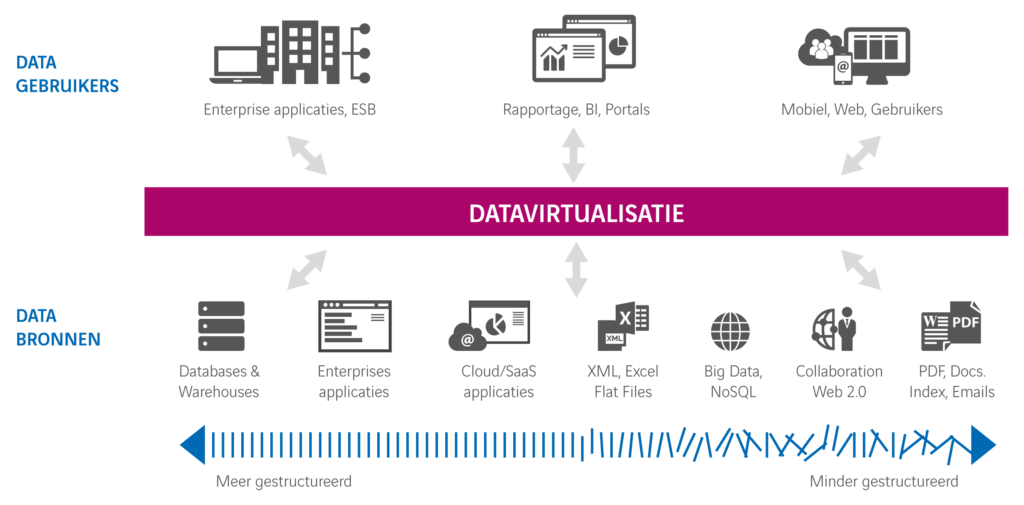
Daar zijn de systemen van veel organisaties echter niet op ingericht. Daardoor kost het ontzettend veel tijd en moeite om gegevens terug te vinden, te rapporteren over data en te monitoren of er compliant wordt gewerkt. Organisaties zoeken daarom naar slimme oplossingen voor dit probleem. Maar het is een bijna onmogelijke opgave om de GDPR in ieder systeem apart te beheren. Het liefst hebben organisaties toegang tot alle persoonlijke gegevens vanuit één centraal punt, zonder dat ze allerlei nieuwe systemen moeten ontwikkelen. Datavirtualisatie maakt dat mogelijk.
Eén centrale plek
Datavirtualisatie creëert namelijk een abstracte informatielaag, waarin data uit verschillende bronnen realtime wordt ontsloten, getransformeerd en geïntegreerd. Zonder dat data wordt gedupliceerd. Je beschikt dus over één centraal ‘dataloket’ voor de toegang tot en het beheer van persoonsgegevens. In een vorige blog schreven we al hoe datavirtualisatie precies werkt en hoe je in vier stappen een goede business case opbouwt voor een datavirtualisatieplatform. Voor het gebruik van de virtualisatielaag is geen technisch kennis nodig over de fysieke opslag van gegevens. Het is een gebruiksvriendelijk virtueel dataloket waarmee je organisatie snel en eenvoudig aan de GDPR kan voldoen, zónder te investeren in nieuwe hardware of het opnieuw opbouwen van bestaande systemen.
Wat houdt de GDPR precies in?
De GDPR stelt een fors aantal eisen aan je organisatie. Sommige daarvan zijn met procedurele maatregelen aan te pakken, maar in veel gevallen gaat het om puur technische eisen. Laten we die eisen eens kort op een rijtje zetten:
- Alleen voor vooraf duidelijk omschreven en gerechtvaardigde doeleinden mogen persoonsgegevens worden verzameld. Die gegevens worden vervolgens alleen verder verwerkt voor die omschreven doeleinden.
- Deze gegevens moeten verwijderd of geanonimiseerd worden als de identificatie van een persoon niet meer noodzakelijk is voor deze doeleinden.
- Persoonsgegevens dienen beveiligd te zijn met deugdelijke technische en organisatorische maatregelen.
- Organisaties moeten een persoon altijd inzicht kunnen geven in welke persoonsgegevens van hem of haar zijn vastgelegd.
- Het verwijderen van persoonsgegevens moet op een eenvoudige manier mogelijk zijn voor een persoon.
- Bij de ontwikkeling van producten of diensten moet gebruikt worden gemaakt van privacy-verhogende maatregelen.
- Persoonsgegevens moeten in een begrijpelijk formaat gedownload kunnen worden door de betreffende persoon.
- Naast je identiteit en het doel van het gebruik van persoonsgegevens moet je als organisatie ook nadere informatie verschaffen (voor zover dat noodzakelijk is) om een behoorlijke en zorgvuldige gegevensverwerking te garanderen.
- Je bent verplicht om inbreuken op de beveiliging te melden als er kans is op ernstige nadelige gevolgen voor de persoonlijke levenssfeer.
Je ziet dat de GDPR veel eisen stelt om de privacy van personen te garanderen. Een centraal dataloket zorgt dat je veel makkelijker aan die eisen kunt voldoen. De GDPR-voordelen van datavirtualisatie zijn samen te vatten in vier punten.
1. Toegang vanaf één punt
Met datavirtualisatie creëer je één centraal loket om de beveiliging en toegang van alle persoonsgegevens eenvoudig en vooral compliant te beheren en te monitoren. Doordat in het loket naast data ook metadata aanwezig is, krijg je op elk moment inzicht in de beveiliging van gevoelige gegevens en kun je hierover rapporteren. Dankzij het logboek zie je wat de originele bron is, welke gebruikers gegevens hebben bekeken, met welk doeleinde zij die gegevens hebben bekeken en of er eventueel wijzigingen zijn aangebracht. Bovendien is het mogelijk om gegevens te maskeren, zodat deze niet zichtbaar zijn voor gebruikers die de vereiste inloggegevens missen. Dergelijke regels kunnen worden toegepast op verschillende systemen.
2. Centrale autorisatie
Bovendien bepaal je vanaf één punt exact wie in je organisatie toegang krijgt tot welke gegevens. De autorisatie beheer je voor alle verschillende systemen – zowel in de cloud als on premise. In de virtualisatielaag kun je specifieke machtigingen toepassen, waaronder op rij- en kolom niveau. Dus je kunt zelfs per bestand bepalen wie wel of geen telefoonnummers of adressen kan zien. Daarnaast zie je in één oogopslag wie welke persoonsgegevens heeft gezien of gewijzigd. Het loket verifieert gebruikers via bestaande protocollen als LDAP, pass-through met Kerberos, Windows SSO, OAuth, SPNEGO-authenticatie en JDBC / ODBC-beveiliging. Je bent met datavirtualisatie dus in staat om geavanceerde regels op te stellen en tot in detail te monitoren wie gegevens heeft gebruikt of bekeken.
3. Faciliteert privacy by design
De GDPR eist dat je organisatie voldoet aan privacy by design. Oftewel dat je al bij de ontwikkeling van je product of dienst goed nadenkt of je persoonsgegevens echt nodig hebt. En zo ja, hoe je deze gegevens gaat beveiligen. Een groot voordeel van het dataloket is dat het privacy by design al faciliteert. Je zorgt vooraf al voor de strikte beveiliging van alle persoonsgegevens. Nieuwe gegevens voeg je ook eenvoudig toe aan de virtualisatielaag. Vervolgens kun je die gegevens aan dezelfde beveiligingscontroles onderwerpen en autorisaties toewijzen.
4. Minder versies van persoonsgegevens
Dankzij datavirtualisatie hoeven er geen kopieën meer gemaakt te worden als gebruikers data nodig hebben. Het dataloket werkt met de bestaande infrastructuur van een organisatie. Data kan echter aan verschillende gebruikers in verschillende vormen en formaten aangeboden worden zonder die data te dupliceren of kopiëren. Door data niet fysiek maar virtueel aan te bieden, voorkom je dat er steeds meer versies ontstaan van persoonsgegevens en wordt het beheersbaarder voor bedrijven om te voldoen aan de eisen van de GDPR.
Datavirtualisatie is dé oplossing om de technische uitdagingen van de GDPR aan te pakken. En dat is nodig ook. Want wie niet voldoet aan de GDPR riskeert boetes die in de tientallen of honderden miljoenen lopen. Met datavirtualisatie voorkom je die boetes, en daarmee verdien je de investering in één klap terug!
Wanneer start jij met het inzetten van datavirtualisatie om de privacy van je klanten te waarborgen?