
Leer in 10 minuten
Datavirtualisatie kan je organisatie veel opleveren. In eerdere blogartikelen heb je al kunnen lezen hoe je orde creëert in al je datastromen. Daarnaast vertelden we hoe je de stap zet naar een logisch data warehouse, zonder dat je de informatiewinkel hoeft te sluiten. We hebben uitgelegd hoe je structuur aanbrengt in dat logische data warehouse met een functionele architectuur en hoe je die vervolgens vertaalt naar een technische inrichting. Bovendien kun je in de Chalk Talk van Rick van der Lans zien welke technische uitdagingen je organisatie kan oplossen met datavirtualisatie.
Graag neem ik je mee om dieper in de technologie van het Denodo Platform voor datavirtualisatie te duiken en de vragen te beantwoorden die vaak komen bovendrijven als een organisatie aan de slag gaat met een datavirtualisatieplatform in combinatie met big data.
Veel bedrijven kiezen voor datavirtualisatie om informatie sneller toegankelijk te maken voor gebruikers. Een van de beloftes van datavirtualisatie is dat je big data eenvoudig kunt integreren in bestaande BI-toepassingen, zoals dashboards en rapportages. Maar hoe doe je dat dan? En blijft de performance van je oplossingen wel voldoende?
In dit artikel leg ik niet alleen uit dat je niet bang hoeft te zijn voor performance problemen als je big data ontsluit via datavirtualisatie, maar ik laat ook zien hoe je daarbij zelfs optimaal gebruik kunt maken van de rekenkracht van big data platformen. Zodat investeringen in bijvoorbeeld data lakes dus niet voor niets zijn geweest. Je gebruikt de kracht ervan juist om de performance van je gehele BI-omgeving een boost te geven.
Je wilt toch niet terug naar de wereld van ETL?
Uit onderzoek van Forrester blijkt dat het aantal organisaties met meer dan 100 terabyte aan data in 2017 steeg naar 59 procent, ten opzichte van 31 procent in 2016. Daaruit kun je vooral opmaken dat bedrijven steeds meer verschillende soorten data – gestructureerd en ongestructureerd, simpel of complex – verzamelen. Data van zowel interne processen als van consumenten, leveranciers en de branche.
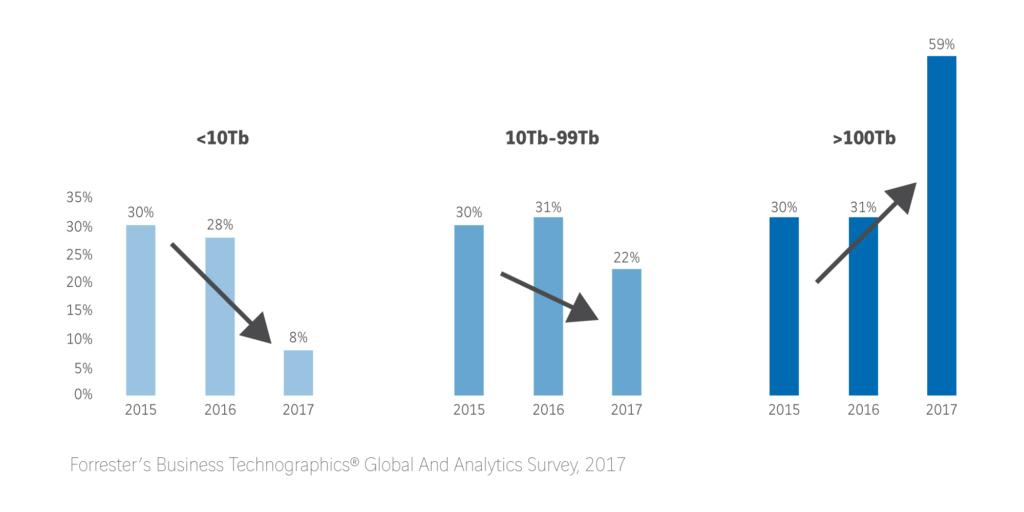
Veel organisaties hebben er de laatste jaren voor gekozen om voor big data bronnen aparte oplossingen te implementeren (bijvoorbeeld een data lake), los van de bestaande data warehouse en BI-oplossingen. Uit de ruwe, ongefilterde en ongestructureerde data in het data lake kan een data scientist dan de informatie ophalen waar de business om vraagt. Volgens leveranciers kunnen organisaties data met een data lake eenvoudig benaderen, integreren en snel beschikbaar maken voor eindgebruikers. Hierdoor zou de behoefte aan het traditionele data warehouse komen te vervallen.
Toch zitten er flink wat haken en ogen aan een data lake. Veel traditionele data warehouses beschikken al over uitstekende functionaliteiten voor de opslag van data en executie van analytische queries. Waarom zou je al die data dan willen verplaatsen naar een data lake? Dat zorgt immers voor redundantie en je wilt juist niet terug naar de traditionele ETL-wereld waarin data veelvuldig gedupliceerd wordt. Bij de implementatie van een data lake moet je bovendien zaken zoals metadata, data governance en security nogmaals inrichten. En mogelijk is er veel privacygevoelige informatie binnen je organisatie die je niet zomaar in een data lake wil opslaan.
Een data lake is erg goed bruikbaar voor data scientists die met ruwe data willen werken. Mensen in je organisatie die behoefte hebben aan dashboards en rapportages halen hun data waarschijnlijk liever uit ‘betrouwbare’ data warehouse bronnen.
Datavirtualisatie als oplossing
Bedrijven zijn daarom op zoek naar een architectuur die kan omgaan met alle bestaande opslaglocaties en databronnen en geen moeite heeft met complexe scenario’s en grote volumes data. Een oplossing waarbij de functionaliteiten van bestaande data warehouses en data marts worden behouden en gecombineerd met de functionaliteiten van big data bronnen en data lakes. En datavirtualisatie is daarvoor de ideale oplossing, omdat daarmee data op een logische manier ontsloten en geïntegreerd wordt, zonder dat replicatie van data nodig is.
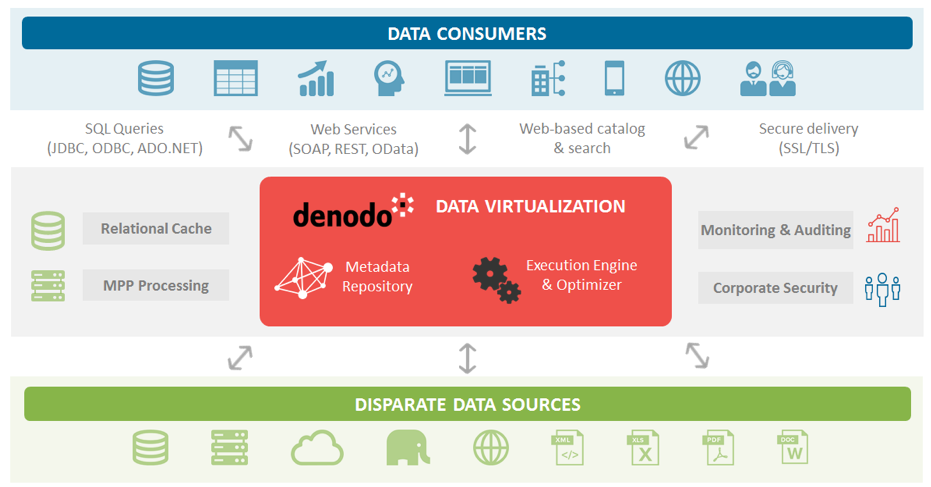
Datavirtualisatie helpt je om dataleveringen efficiënter uit te voeren en geeft je meer flexibiliteit om veranderingen door te voeren met minder beheerinspanning. En bovendien kun je eenvoudig inzichtelijk maken hoe datasets tot stand zijn gekomen, wie toegang heeft tot welke data en welke informatie precies wordt uitgevraagd.
Met een datavirtualisatieplatform als Denodo is het mogelijk om een big data bron of data lake op te nemen en te integreren met andere bronnen en bestaande data warehouses in één architectuur. Denodo biedt standaard connectoren naar alle grote SQL-on-Hadoop engines, van Hive en Impala tot SparkSQL en Presto. Ook kan data rechtstreeks gelezen worden uit opslaglocaties van Hadoop HDFS.
Performance met Denodo
Denodo maakt – naast performance optimalisatie binnen het platform zelf – slim gebruik van functionaliteiten van de onderliggende databronnen om de performance te optimaliseren. Je krijgt dus the best of both worlds. Het datavirtualisatieplatform maakt daarbij maximaal gebruik van de rekenkracht van onderliggende big data bronnen en data lakes:
- Big data als pushdown & transfer engine
- Big data als cache voorziening
- Big data als massive parallel processing platform
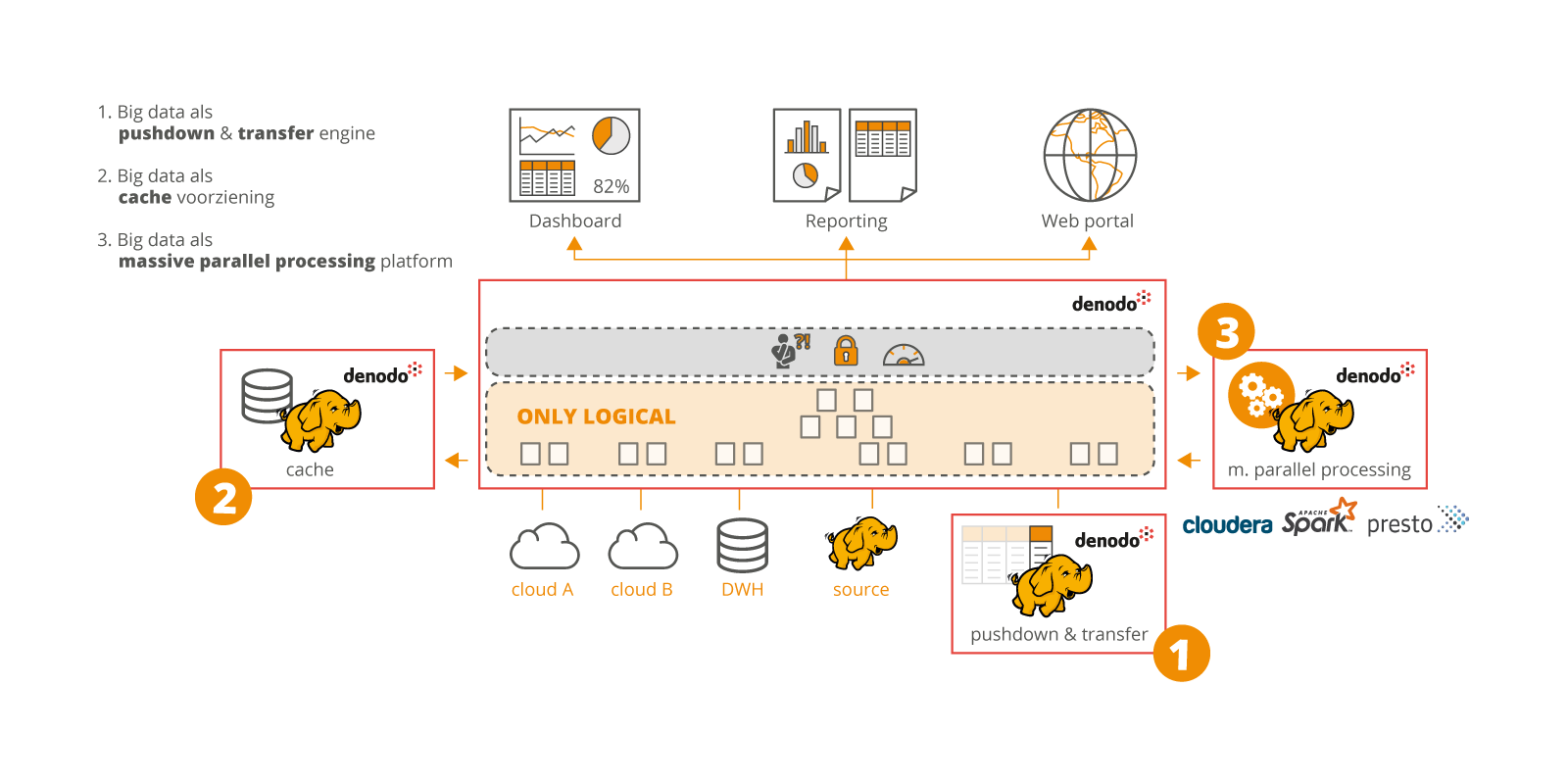 1. Big data als pushdown & transfer engine
1. Big data als pushdown & transfer engine
De rekenkracht van een big data bron kan gebruikt worden om processingkracht buiten Denodo te benutten. Denodo maakt gebruik van een cost based optimizer. Deze tool kijkt per query of de Denodo-server sterk genoeg is om de opdracht virtueel uit te voeren of dat er beter gebruikgemaakt kan worden van de processingkracht van een big datasysteem.
2. Big data als cache voorziening
Big data platformen zijn binnen Denodo te gebruiken als cache voorziening, waarbij geselecteerde data uit een andere bron naar de big data bron geschreven wordt om later weer uit te lezen. Denodo voert de regie hierop volledig zelf uit.
- Een target tabel wordt aangemaakt in een SQL-on-Hadoop systeem
- Brokken data (parquet files) worden lokaal aangemaakt
- Die data wordt parallel weggeschreven naar Hadoop
3. Big data als Massive Parallel Processing (MPP) platform
Voordat Denodo 7.0 uitkwam waren er drie manieren om queries te verwerken.

- Simple Federation – De traditionele ‘naïeve strategie’. Haal alle data op, sla het op ‘in memory’, voer dan de join uit en vervolgens de group by.
- Shipping – Maak een tijdelijke tabel aan in een van de bronsystemen en verplaats alle data daar naartoe. De join en de group by worden daar uitgevoerd. Denodo ontvangt daarna het resultaat. De kracht van de gegevensbron wordt gebruikt om het werk te doen.
- Partial Aggregation Pushdown – Deze functionaliteit laat de bron zoveel mogelijk zelf doen. Denodo haalt de dataset op met een group by en voert de opdracht virtueel uit.
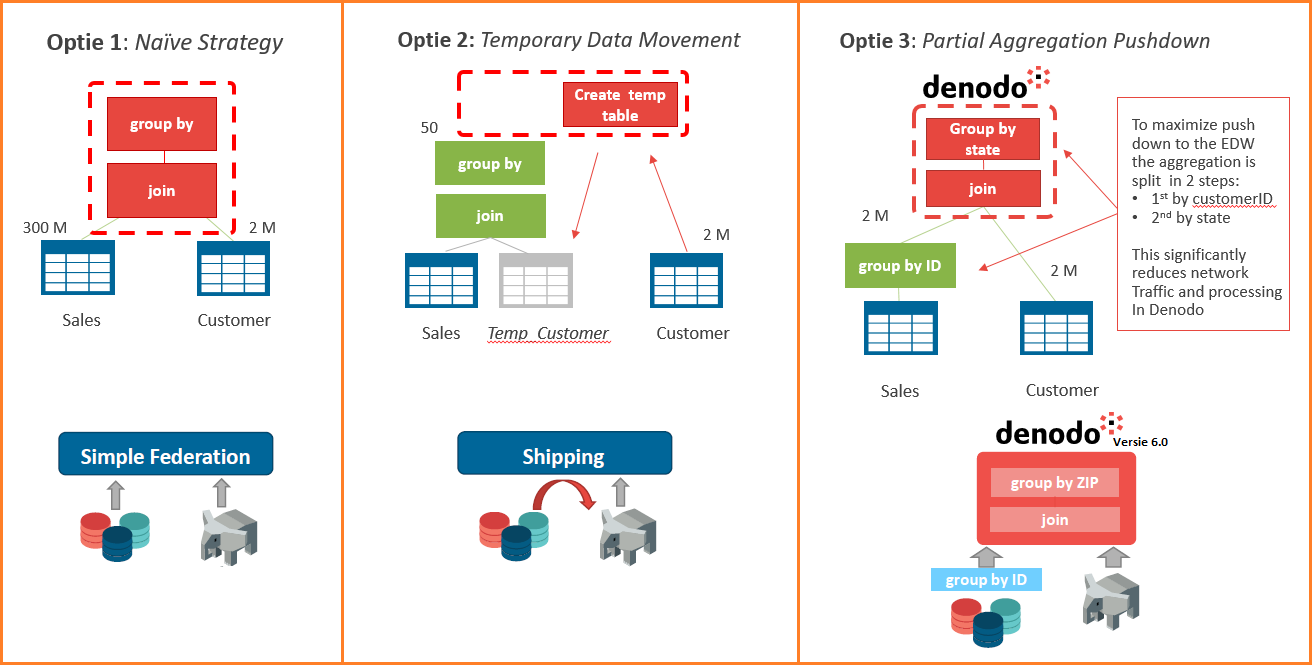
Met de komst van versie 7.0. heeft Denodo nu ook zeer krachtige MPP-functionaliteit geïntroduceerd in het platform. Deze is gebaseerd op de Partial Aggregation Pushdown, maar gebruikt de rekenkracht van een big data systeem in plaats van het Denodo platform. De verwerking van de query wordt dus geheel of gedeeltelijk verplaatst naar de onderliggende MPP-databron. Je krijgt als het ware gratis MPP-functionaliteit in het datavirtualisatieplatform. Deze functionaliteit is beschikbaar voor drie Hadoop-engines: Spark, Presto en Impala.
Al deze functionaliteiten werken nauw samen om complexe query’s met grote datavolumes op een efficiënte manier uit te voeren door gebruik te maken van reeds beschikbare MPP-oplossingen. Met een geweldige performance tot gevolg.
Landschap voor alle bronnen en systemen
Voor organisaties met grote hoeveelheden data is het datavirtualisatieplatform de ideale oplossing om BI-oplossingen en big data bronnen te integreren in één architectuur. In plaats van eindeloos data te kopiëren, zorgt datavirtualisatie ervoor dat data altijd snel en eenvoudig beschikbaar is. Inzichten uit big data komen daarmee ook beschikbaar voor eindgebruikers in dashboards, rapportages en BI-tools. Zónder in te leveren op performance en door optimaal gebruik te maken van alle onderliggende databronnen en systemen in het IT-landschap. Zo worden dataleveringen efficiënter uitgevoerd, worden organisaties flexibeler om veranderingen door te voeren en is er aanzienlijk minder beheer nodig. Bovendien is er meer inzicht waar data vandaan komt, wie toegang heeft tot de data en welke gebruiker wat voor data heeft gebruikt. Wat wil je nog meer als organisatie?
Wat zou het jouw BI-gebruikers opleveren als ze zelf snel en eenvoudig toegang krijgen tot big data?